

Sometimes you have to be a bit too optimistic to make a difference - Linus torvalds
My background has always been a Software Engineer; however, in the last three years of my career, I have moved so close to working with data that my role has changed to something more close to a Software Data Engineer. I did not even know the meaning of this role some years ago, and, by the way, I had this joke with my friends that the amount of data generated each year is proportional to the new concepts/roles born each year in tech. So very likely you don't know the meaning of this role, I define empirically the Software Data Engineer role as someone who creates technology solutions driven by data.
The Takeaways
Software data engineering comes from Data Engineering + Software Engineering, Both fields, Data Engineering and Software Engineering, have many differences. They are indeed two different worlds, they have different methodologies, different concepts for the same word (a lot of funny stories there) and different understanding for the concept of good practices. When the strategies are executed right, you will have the good of them, but also you can end up with a chaotic reality having the worst of both sides. Even though the developing complexity increase dramatically mixing them, it is good to remember that they have in common something powerful, the word 'engineering', that in short creates a similar goal: resolving problems using technology. The following are five takeaways that I've learned in this journey.
Data as decision-making
By 2023, there were 328.77 quintillion bytes of data created each day, and by 2018, 90% of the existing data was generated in only two years. These are huge numbers, and they are only going up. That changes the rules; modern software architectures rely on data to develop scalable and reliable products. Early cycles of the software, such as design thinking and planning, use data as a driver. Companies that are mature, and also startups, understand the value of data very well, since they are evolving they business model adapting to the new AI era. This new understanding brought a new revelation, data inside software architecture should not be perceived as information to store, but as an asset to use in decision-making.
Default configurations default problems
Nowadays, a lot of technologies and frameworks come ready to use, even ready to go into production. Without a doubt, these new technologies accelerate the delivery process, don't they? Configuration parameters play a crucial role in long-term solutions; they can bring unexpected behavior that requires a long troubleshooting time to find the reason for that. The most popular issues that I've found are:
- AWS VPC connection problems with databases
- Slow queries generated by different frameworks
- Strange behavior because a parameter is on by default
- Confidential data exposed
- unexpected costs
And the list continues. One tool that helps to avoid these problems is building a POC that includes digging deep into the configuration parameters, focusing on the default values, to have a complete understanding of the default behavior and how to change it.
Don't reinvent the wheel
When we refer to use cases about data ingestion, our software developer instinct makes us think of developing a new app/API from scratch to resolve the problem. The reality is that most of the issues requiring data pipelines have already been resolved. Reinventing the wheel carries concerns such as scalability, maintainability, and resilience to failures.
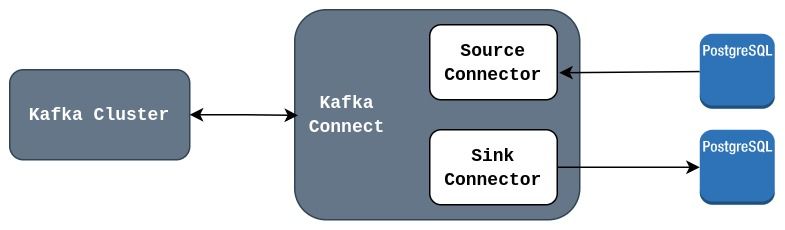
The best use case is Kafka connect Show Figure 1. I will write a new article about it soon. But to summarize, Kafka Connect is a framework that works as a proxy to stream data from one technology to another. It uses declarative configuration instead of code, saving at least 80% of the time when writing consumer and producer apps. Technologies like this are the solutions that really make a difference for companies in this new era. I said before, and I will say again, technology is a tool to resolve problems and choosing the right one is what makes an engineer's decision a good decision (even if that decision implies no coding).
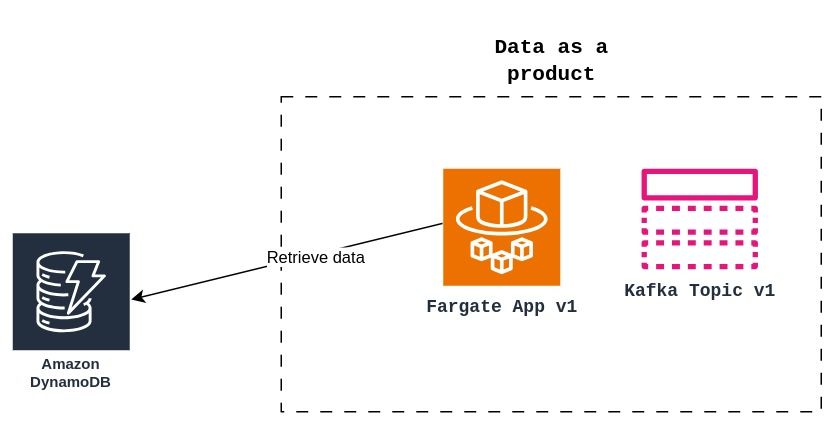
Data product is a unit. AKA “Data Quantum”.
There is a concept in data mesh that stands for seeing data as a product. It implies, like other products, having a life cycle, clear consumers, and a clear value proposition. That said, versioning data products also implies versioning every component of these. Data products are not just repositories of information; they are also dynamic assets that contain components in different technologies. For example, a data product that requires information from a DynamoDB uses a Python app deployed in AWS Fargate to retrieve this data, Show Figure 2.
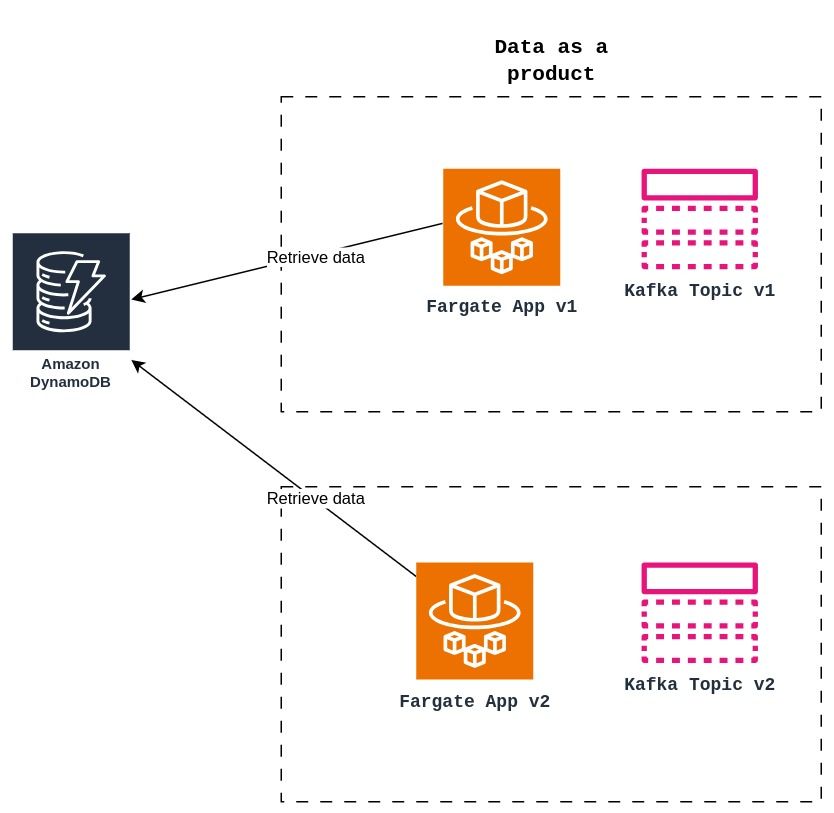
As the figure shows, the data product is not just the data, but also the Fargate app and other tools it can contain. For the example, it implies that each version of the data product will necessitate a new version of the Fargate app. Each time the data has a new version, the tools have to evolve together, Show Figure 3.
Dashboards and monitors are heroes
Developing new software using data as a driver involves data flowing through different technologies, most probably using event-driven architecture. Tracking and debugging are among the biggest challenges in this modern architecture. It involves not only different architectures, such as monolithic and microservices, but also various open technologies like Python, TypeScript, and Go, and even closed technologies like Tableau. Collecting metrics, logs, and performance insights in each data store system is just a basic thing that needs enhancement using dashboards, monitors, and notifications using Slack channels or email. I would recommend technologies such as Datadog, the ELK stack, AWS CloudWatch, and Sentry.