

Hace poco revisaba una carpeta que tenía en mi lapto, y me encontré que contenía cierta cantidad de "casos de prueba", que en su momento se han convertido en un dolor de cabeza, y lo digo así por qué a pesar de que casi siempre no son errores, si es importante para mi entender por qué funcionan y a medida que las librerías o frameworks se hacen más nuevos o con menos comunidad, es más difícil encontrar la respuesta. El mundo del desarrollo de software es relativamente nuevo, estamos aprendiendo sobre la marcha y por eso las tecnologías varían y cambian tan frecuentemente, a veces a un ritmo que es difícil de seguir, esto lo viven muchas librerías que se deprecan o pierden soporte, incluso también puede ocurrir que la nueva versión genera algún error, podría casi que afirmar que a muchos nos ha pasado la situación de la Figura 1 y esta situación es un poco frustrante, incluso terminamos en el repositorio del código de la librería entendiendo esa lógica y tratando de entender su estructura, las siguientes son conclusiones resultado de un proceso de prueba y error en diferentes situaciones

Pytest mock, que mockea y por qué no funciona?
Cuando trabajamos haciendo pruebas, es necesario realizar mocks, un mock es básicamente encapsular el comportamiento de una librería / método y simular un comportamiento diferente, esto ya que en las pruebas unitarias no se deben afectar servicios de terceros, en pytest utilizamos una librería llamada pytest-mock, este es un wrapper de unitest.mock para permitir la integración con pytest, en su documentación podemos intuir que podemos generar diferentes situaciones, en sí la librería es muy buena, pero su documentación está un poco limitada al conocimiento de la librería unitest.mock. Un caso que se usa mucho es el método mocker.path, pero realmente no está muy claro: cómo se mockea, que y cuando, veamos el siguiente ejemplo con los siguientes archivos
class CreateUser:
@staticmethod
def run():
raise Exceptionfrom src.create import CreateUser
def register():
CreateUser.run()
return TrueSi queremos realizar el test del archivo main.py y debemos hacer un mock de la clase CreateUser como se puede hacer?, leyendo la documentación se podría llegar a esta conclusión
from src.main import register
from pytest_mock import MockFixture
class CreateUserFaker:
@staticmethod
def run():
pass
def test_register(mocker:MockFixture):
mocker.patch("src.create.CreateUser", CreateUserFaker)
assert register()==True
ejecuto el test y obtengo el siguiente resultado

falla porque el mocker no está funcionando, y esto porque el mocker se está aplicando mal, la conclusión es sencilla, se mockea el módulo utilizando la dirección del módulo que sea testea, más fácil, se mockea el módulo donde se importa y no donde está escrito, así que cambiando el código del test quedaría así
from src.main import register
from pytest_mock import MockFixture
class CreateUserFaker:
@staticmethod
def run():
pass
def test_register(mocker:MockFixture):
mocker.patch("src.main.CreateUser", CreateUserFaker)
assert register()==True

Variables de entorno en pytest
En el desarrollo de algunos test puede requerirse tener información de variables de entorno de prueba en memoria, esto puede ocurrir por diferentes entornos y contextos, hay varias formas, utilizando conftest, cargando la variable cuando se necesite, etc., una opción factible es utilizar pytest-dotenv, de esta forma podemos agregar la siguiente configuración
[pytest]
env_files =
.test.envDATABASE_NAME=testde esta manera se puede centralizar qué variables deben estar cargadas en memoria para que el test pueda obtener un buen resultado, y esto directamente le comunica al desarrollador que deben existir estos datos
Comportamiento en los modelos en pydantic
La capa de dominio sin duda tiene responsabilidades y comportamientos más allá de solo datos, por esto cuando modelamos nuestra información, muchas veces necesitamos agregar comportamiento, cuando utilizamos pydantic es muy simple, pero quizás no es tan obvio, para ello veamos el siguiente ejemplo
from pydantic import BaseModel
from datetime import date
class Insurance(BaseModel):
effective_date: date
si quisiera saber si la fecha de un seguro es vigente, es decir si su fecha de vigencia supera la fecha de consulta, esta respuesta la puede responder el modelo, por eso el modelo puede tener su propio comportamiento, por consiguiente, agregar un método es muy sencillo, recuerden que al final del día todo se convierten a clases de Python
from pydantic import BaseModel
from datetime import date
class Insurance(BaseModel):
effective_date: date
def is_valid(self):
return self.effective_date > date.today()
print(Insurance(effective_date=date(year=2022, month=11,day=12)).is_valid())de esta forma, el objeto que se cree de tipo insurance, tendrá la capacidad de responder si está vigente o no
Excepción capturada en la lambda, pero comportamiento erróneo
Hay un error que puede ocurrir y puede tomar bastante tiempo encontrarlo, y es por la naturaleza del funcionamiento de las lambdas, cuando una lambda se invoca por medio de otra lambda u otro servicio de AWS que no sea API Gateway la respuesta puede viajar en formato JSON, si dentro del desarrollo de la comunicación de las lambdas se maneja en este formato, cuando llegue a una lambda que trabaje con salida a la API Gateway, puede mantenerse este formato y generar una excepción veamos el siguiente ejemplo
def register(event, context):
try:
get_support()
user_info = json.loads(event["body"])
user_table = dynamodb.Table(TABLE_NAME)
logger.info(user_info)
response = user_table.put_item(Item=user_info)
logger.info("User created")
logger.info(response)
response = requests.get("https://jsonplaceholder.typicode.com/todos/1")
user = response.json()
return {"statusCode": 200, "body": user}
except SupportNotFound as error:
logger.exception(error)
sentry_sdk.capture_exception(error)
return {"statusCode":400, "body":{"error":"error"}}
except Exception as error:
logger.exception(error)
sentry_sdk.capture_exception(error)
return {"statusCode":400, "body":{"error":"error"}}
ejecutamos y obtenemos el siguiente resultado
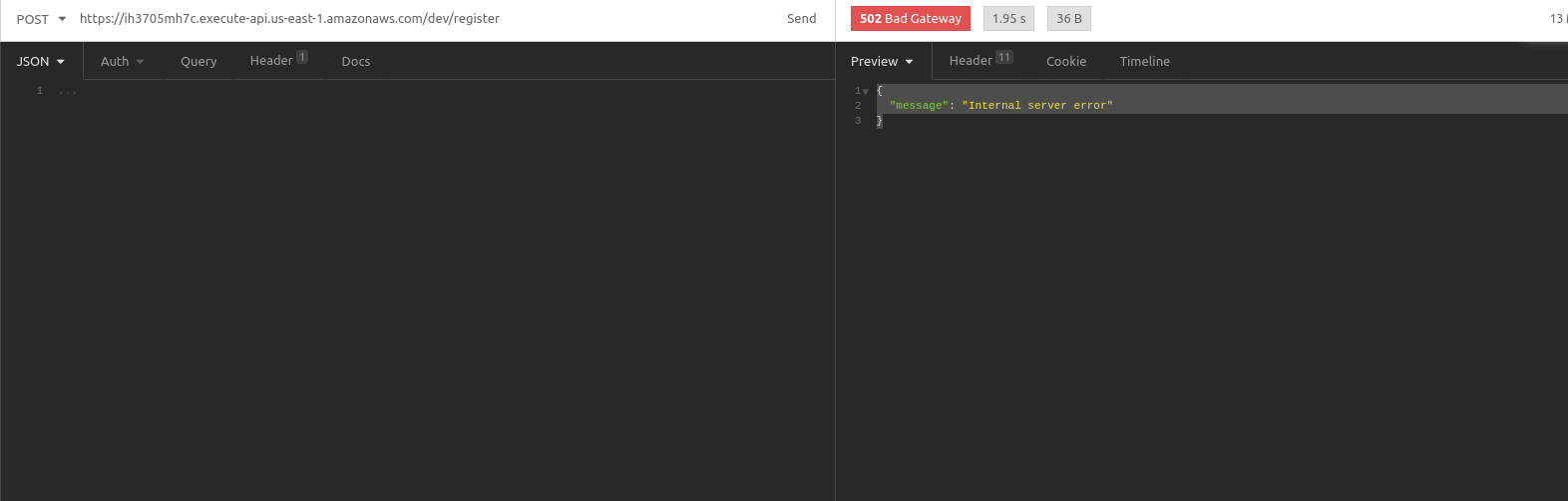
la confusión puede venir en el código anterior, en donde se supone que en el try hay un espacio para capturar todas las excepciones y se esperaría que si sucede, este llegaría aquí, lo que pasa en este caso es que la excepción ocurre en un momento en donde ya la lambda envió la respuesta y es procesada en la API Gateway por eso la excepción no es capturada dentro de la lambda, por ello todo error 502 está totalmente ligado al formato en que se responde, generalmente es algún encode o decode que se olvidó hacer y que por su naturaleza las lambdas no logran capturar, la solución es enviar la respuesta en json.dumps
def register(event, context):
try:
get_support()
user_info = json.loads(event["body"])
user_table = dynamodb.Table(TABLE_NAME)
logger.info(user_info)
response = user_table.put_item(Item=user_info)
logger.info("User created")
logger.info(response)
response = requests.get("https://jsonplaceholder.typicode.com/todos/1")
user = response.json()
return {"statusCode": 200, "body": json.dumps(user)}
except SupportNotFound as error:
logger.exception(error)
sentry_sdk.capture_exception(error)
return {"statusCode":400, "body":json.dumps({"error":"error"})}
except Exception as error:
logger.exception(error)
sentry_sdk.capture_exception(error)
return {"statusCode":400, "body":json.dumps({"error":"error"})}una opción muy buena puede ser utilizar un wrapper que se encargue de encodear la respuesta en caso de que no se envíe correctamente, esto se puede lograr utilizando AWS wrapper tool, la cual es una herramienta muy interesante donde podríamos hablar de ella en otro post
Conclusiones
Todas las herramientas van a presentar siempre situaciones en donde seguramente no está explícitamente que se debe hacer, y muchas de estas situaciones desencadenan procesos donde se involucra el consultar en diferentes fuentes de información, este proceso es un proceso que se debe mejorar a medida que se presente, porque según mi experiencia, existe una relación directa entre esta capacidad de research y el proceso de mejora como desarrollador
¿Te gusto el post y quisieras poder aplicar lo aprendido?
