

Las pruebas de carga dentro del ambiente del software son necesarias, no solamente por que hacen parte de los planes de pruebas a los que se somete un sistema, sino que además permite validar con las diferentes integraciones esos acuerdos de calidad de servicio que te venden los diferentes proveedores Ver Figura 1, con esto se puede validar que realmente se están cumpliendo estos SLA, adicional a esto permite conocer tu producto, qué capacidad tiene y cuándo puede fallar, con esto se pueden mantener planes de acción que estén relacionados a un monitoreo constante, es decir estar preparado para lo que pueda pasar

Locust
Actualmente cuando se quiere hacer pruebas de carga probablemente se piensa en apache jmeter o cualquier otra grande cantidad de herramientas por uso que existen, estas herramientas están bien, pero la verdad muchas de ellas son un poco limitadas o no ofrecen todas sus funcionalidades disponibles, si vienes de python o has programado en python, se te hara una herramienta bastante interesante, locust está hecha para hacer testing a servicios y aplicaciones, es una herramienta que es scriptable, esto quiere decir que se puede personalizar agregando implementaciones propias de código hechas en python con una complejidad baja, ademas a pesar de que la herramienta usa coroutines, la complejidad se abstrae dejando al usuario una implementación de python puro
Ejemplos
primero se debe instalar, para ello crearé un entorno virtual y lo instalare con el siguiente comando
pip install locust
como mencione locust es una herramienta scriptable, para ello construire ese script en un archivo python por defecto debe llamarse locust_file.py, pero veremos que con el cli se puede pasar como parámetro el nombre, en mi caso llamare al archivo main.py y escribire el siguiente codigo
from locust import HttpUser, task, between, tag
import time
fake_gamer = {
"name": "Fake Gamer",
"description": "Fake Gamer",
"price": 200000,
"item": {"name": "Fake Item", "price": 200000, "is_ofter": True},
}
class User(HttpUser):
@task
def create_gamer(self):
self.client.post("/gamer", json=fake_gamer)
wait_time = between(0.5, 10)
@task(3)
def get_person(self):
for person_id in range(1, 4):
self.client.get(f"/person/{person_id}", name="/person")
time.sleep(1)
para ejecutarlo utilizó el cli de locust con el siguiente comando
locust -f main.py --web-port 15000se ingresa a la url en mi caso localhost:15000 y se debe llenar la cantidad de usuarios que se generarán, y el host target, este debe ser la url principal, en mi caso es un servicio local corriendo en el puerto 8000
Luego de ello se inicia la carga y se pueden ver los siguientes gráficos
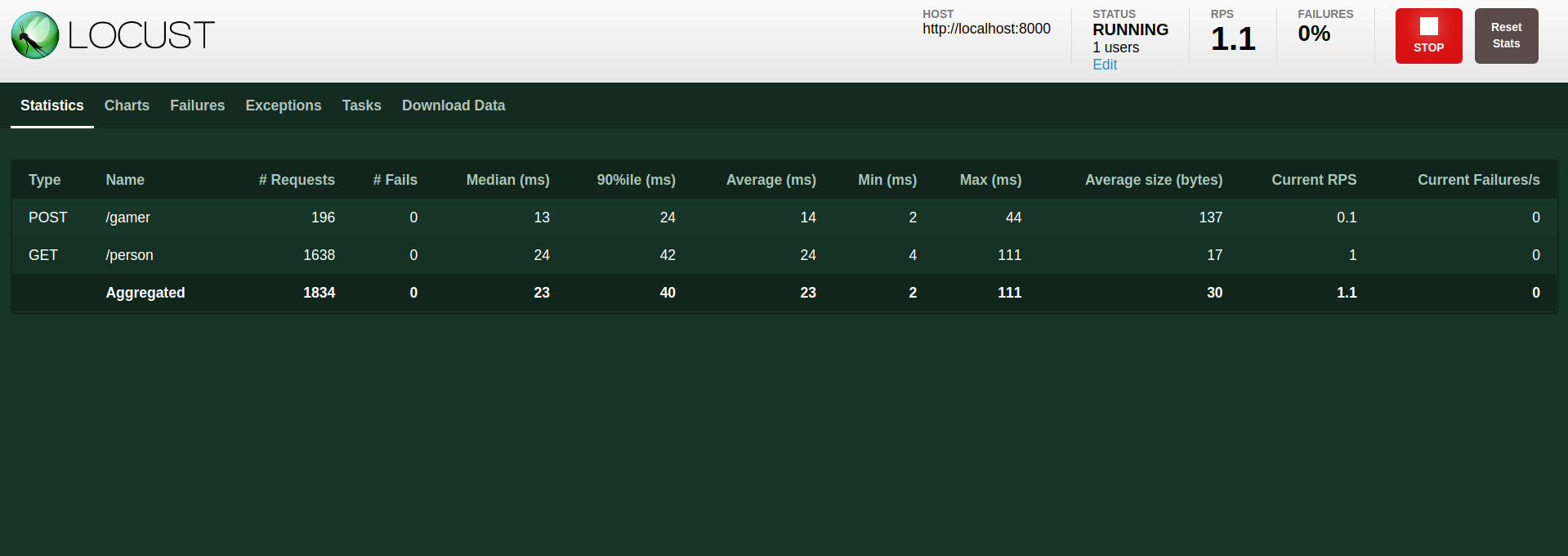
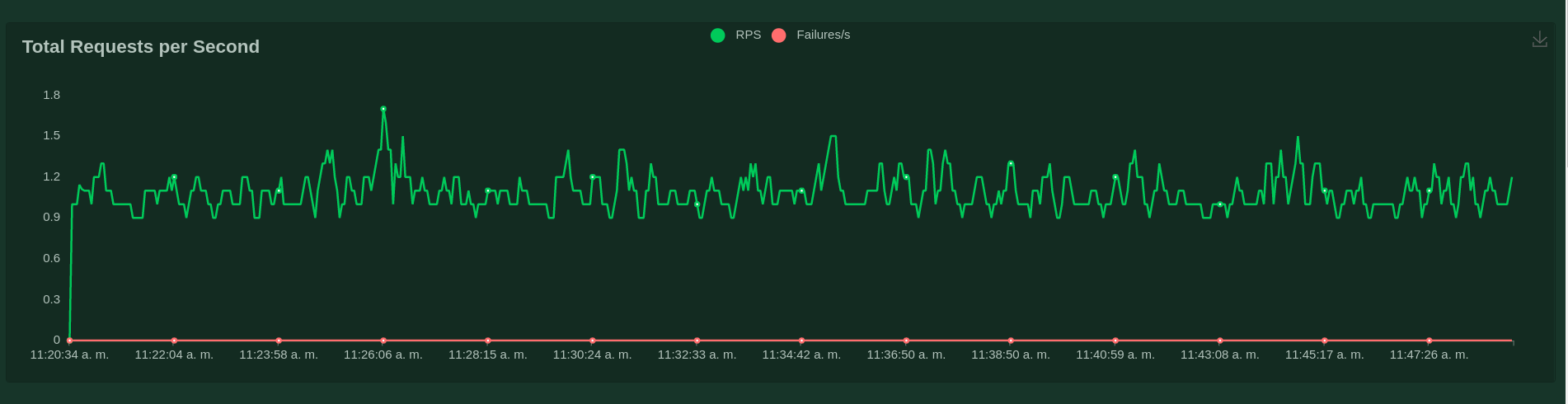
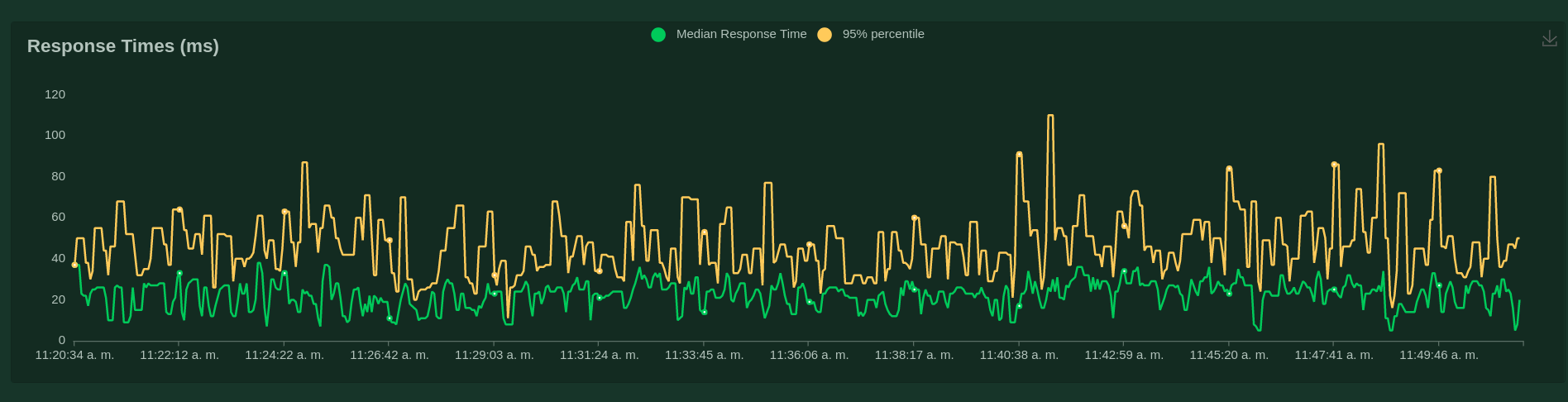
ahora revisemos un poco el código anterior, a pesar de que por debajo la complejidad de las coroutines existe, lo que expone locust es más sencillo, locust usa el concepto de users, cuando se realiza las pruebas de carga se realiza por usuarios (como vimos en la interfaz), por ello se debe crear una clase, en este ejemplo llamada User que debe heredar de HttpUser, esta clase representará a cada usuario que se usará para hacer la prueba, es decir serán objetos, por ello si tengo 10 usuarios para probar tendría 10 objetos de esta clase, el concepto clave aquí son las task, es decir las tareas que realizará cada usuario, como se ve en el código una task se declara utilizando el decorator @task como se aprecia a continuación
@task(3)
def get_person(self):
for person_id in range(1, 4):
self.client.get(f"/person/{person_id}", name="/person")
time.sleep(1)las tareas que tendrá cada usuario, es decir cada prueba que realizará, se ejecutan al azar, en el ejemplo anterior yo escribí dos tareas create_gamer y get_person, sin embargo utilizando como parámetro un weight en la tarea get_person uso un weight de 3, esto aumenta la probabilidad 3 veces de que seleccione la tarea get_person y la ejecute, el código dentro de las tareas son peticiones http utilizando una interfaz expuesta por locust de la librería requests, el código puede tener la lógica que desea, en mi caso realizo peticiones con diferentes ids generados por range, esta misma tarea para fines estadísticos las agrupo todas con el mismo nombre /person, ya que son urls diferentes (/person/1, person/2 etc).
Otro ejemplo interesante es agregando un poco de lógica de negocio, que es donde se ve la ventaja de locust, por ejemplo veamos el siguiente código
from locust import HttpUser, task, between, tag
import time
fake_gamer = {
"name": "Fake Gamer",
"description": "Fake Gamer",
"price": 200000,
"item": {"name": "Fake Item", "price": 200000, "is_ofter": True},
}
class User(HttpUser):
@task
def create_gamer(self):
self.client.post("/gamer", json=fake_gamer)
wait_time = between(0.5, 10)
@task(3)
def get_person(self):
for person_id in range(1, 4):
self.client.get(f"/person/{person_id}", name="/person")
time.sleep(1)
@tag("stores")
@task
def get_store(self):
for store_id in range(1, 4):
with self.client.get(
f"/store/{store_id}", catch_response=True, name="/store"
) as response:
if response.json()["store_id"] != store_id:
response.failure("Got wrong store")
esta vez quiero ejecutar para los usuarios, sólo la tarea con la etiqueta store, para ello ejecuto el siguiente comando
locust -f main.py --web-port 15000 --tags storesy observemos las gráficas obtenidas


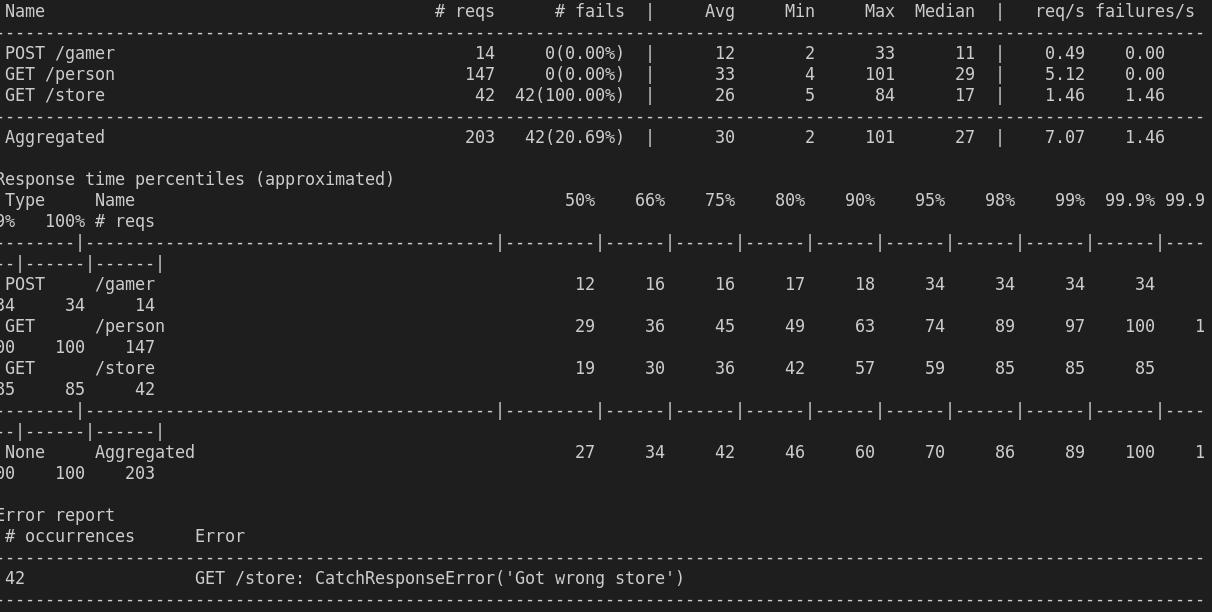
se obtiene 100% falló, a pesar de que el response es exitoso, yo modifique el código de mi servicio a probar, para que retornara un id diferente, por ello como se vio en el código de get_store, si el id es diferente a pesar de que sea una respuesta exitosa, se marca como error, a continuación se aprecia el segmento de código
@tag("stores")
@task
def get_store(self):
for store_id in range(1, 4):
with self.client.get(
f"/store/{store_id}", catch_response=True, name="/store"
) as response:
if response.json()["store_id"] != store_id:
response.failure("Got wrong store")adicional como ven al ser una interfaz de requests, tiene todos los métodos disponibles, en este caso .json() para poder manipular información retornada como un dict, para finalizar si no te gusta la interfaz web o si deseas realizar una integración con una herramienta que automatiza este proceso, se puede ejecutar solamente por consola, para ello se define un archivo locust.conf (para ver más sobre las variables de configuración pueden ir a su documentación)
host http://localhost:8000
locustfile main.py
headless
users 100
spawn-rate 1
run-time 30se ejecuta desde consola locust
locustse obtiene el siguiente resultado
Conclusiones
Al pasar por varias herramientas y servicios de carga, siempre me encuentro con limitaciones, sobre todo con reglas de negocio, bien sea por limitación de rps ya que pueden ser servicios de ambientes dev y limitación en las respuestas, locust me ha brindado una herramienta no solamente para hacer pruebas si no que además es extensible o como ellos lo llaman hackeable, por lo tanto permite generar casos de prueba complejos, es una herramienta fácil de instalar, implementar y además es open source, por todo esto creo que si ya usas una herramienta podrías darle la oportunidad y seguramente obtendrás muy buenos resultados