
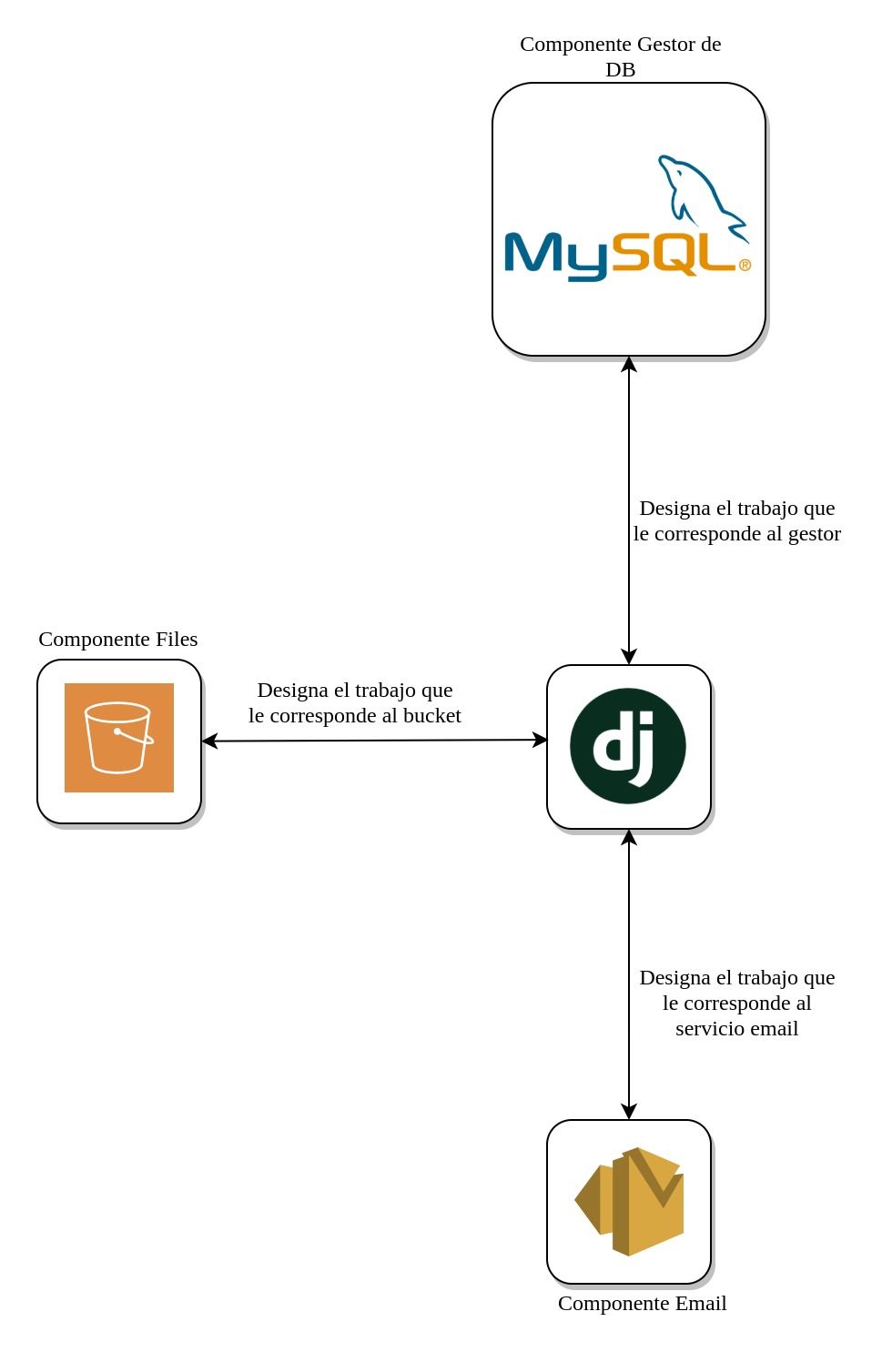
Siguiendo el hilo del artículo anterior en este post seguiremos hablando de rendimiento en relación con las consultas a la base de datos por medio del ORM de django, hace poco leía un artículo sobre código pythonico bastante interesante pero a veces llevar este concepto dentro de las consultas del ORM o uso de cualquier componente externo podría llevar a tener problemas de rendimiento (ver Figura 1) es decir si un componente de email ya tiene su configuración para envío masivo simplemente hay que pasarle los parámetros requeridos para que este servicio lo ejecute, igualmente con los gestores de bases de datos muchos ya permiten realizar consultas que mejoran el rendimiento de manera significativa por ello es importante conocer estas consultas y conocer cómo se pueden ejecutar desde el ORM para designar este trabajo al gestor y no cargarle procesamiento innecesario a la aplicación
Entrando en contexto del ORM de django uno de los errores más comunes que cometemos es cuando queremos conocer la cantidad de datos que existen, en este caso usare el mismo proyecto de el post anterior
Contar la información
from mycars.models import Person
count_data = len(Person.objects.all())
print(f"Data in db {count_data}")el resultado en consola seria el siguiente
Data in db 10120cómo podría obtener un mejor rendimiento? con un pequeño cambio
from mycars.models import Person
count_data = Person.objects.count()
print(f"Data in db {count_data}")el resultado en consola sería el mismo
Data in db 10120por que es mejor la segunda opción? esto se debe a la consulta SQL que por debajo se está ejecutando la primera consulta ejecuta lo siguiente
SELECT "mycars_person"."id", "mycars_person"."name" FROM "mycars_person"en la segunda opción se ejecuta la siguiente consulta
SELECT COUNT(*) AS "__count" FROM "mycars_person";en la primera ser trae toda la información de esa entidad y se dice pythonica, por que desde python se recorre y se cuenta utilizando la función len() en cambio de manera eficiente la segunda consulta cuenta los registros dejando esta carga en el gestor de base de datos
Información necesaria
Aquí mencionaremos un cambio que puede mejorar el rendimiento de nuestras consultas, este será en traer solo la información que necesitamos ya que a veces se tienen entidades con grandes campos y en nuestras consultas necesitamos solamente dos o tres, veamos un ejemplo
from mycars.models import Person
data_filter = Person.objects.all().values("name")
for data in data_filter:
print(data)y la salida en consola seria la siguiente
{'name': 'jacob'}
{'name': 'daniel'}
{'name': 'miguel'}y esta seria la consulta SQL generada
SELECT "mycars_person"."name" FROM "mycars_person" WHERE ("mycars_person"."id" >= 1 AND "mycars_person"."id" <= 3el resultado genera una lista de dicts con los atributos solicitados, ahora también si se desea se puede realizar consultas para evitar traer atributos no deseados
from mycars.models import Person
data_filter = Person.objects.all().defer("name")
for data in data_filter:
print(data)en el query anterior la función defer evita que se traiga el atributo name, pero los demás atributos de la entidad si son cargados
Llaves Foráneas
Cuando se requiere cargar información donde se tiene relación unos a muchos podemos utilizar select_related para mejorar el rendimiento
from mycars.models import Vehicle
vehicles = Vehicle.objects.all().select_related('owner')
for vehicle in vehicles:
print(vehicle.owner)en nuestra consulta anterior se ejecuta un join a la base de datos en donde se trae la información de la table Person como se aprecia en el siguiente query SQL
SELECT "mycars_vehicle"."id", "mycars_vehicle"."color", "mycars_vehicle"."owner_id", "mycars_person"."id", "mycars_person"."name", "mycars_person"."last_name", "mycars_person"."age" FROM "mycars_vehicle" INNER JOIN "mycars_person" ON ("mycars_vehicle"."owner_id" = "mycars_person"."id")esto evita que dentro del ciclo se genere un query SQL a la tabla Person por cada registro variando 'id' como se aprecia en la consulta a continuación
SELECT "mycars_person"."id", "mycars_person"."name", "mycars_person"."last_name", "mycars_person"."age" FROM "mycars_person" WHERE "mycars_person"."id" = 1Crear registros al tiempo
La forma por la cual ingresamos un registro a la base de datos por django es bien usando el método .save() de una instancia o el .create() esto funciona bien cuando se trabaja con pocos registros pero algunas veces se necesita guardar información en grandes cantidades, para ello se dispone de la función bulk_create() que permite crear varios registros en un mismo query evitando ejecutar varios insert veamos el ejemplo en código
from mycars.models import Person
data_to_create:List = []
for _ in range(10):
data_to_create.append(Person(name="name"))
Person.objects.bulk_create(data_to_create)aquí podemos ver el query que ejecutó django
INSERT INTO "mycars_person" ("name", "last_name", "age") SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULL UNION ALL SELECT \'name\', NULL, NULLpodemos ver también cómo sería ejecutarlo dentro de un ciclo utilizando la creación que se usa normalmente
from mycars.models import Person
for _ in range(10):
p1 = Person(name="name")
p1.save()y la traducción de las consultas sql se aprecia a continuación (esa consulta se ejecuta 10 veces una por cada llamado al método save())
INSERT INTO "mycars_person" ("name", "last_name", "age") VALUES (\'name\', NULL, NULL)adicionalmente podemos ver el tiempo que marca las consultas en ejecutarse, la primera utilizando el bulk_create nos marca 'time': '0.000' y cada consulta ejecutada en el segundo método marca en promedio 'time': '0.006'
Actualizar información
Actualizar información es una función que se utiliza bastante, en django se utiliza generalmente traer la información de un objeto que se desea actualizar, setear sus atributos y luego ejecutar el método .save(), sin embargo el parámetro update_fields es muy importante ya que evita actualizar información innecesaria, veamos el código
from mycars.models import Person
p1 = Person.objects.get(id=1)
p1.name = "Jacob"
p1.save(update_fields=['name'])la consulta que se crearía sería la siguiente
UPDATE "mycars_person" SET "name" = \'jacob\' WHERE "mycars_person"."id" = 1'ahora si no se establece el parámetro update_fields django automáticamente genera una consulta donde se actualizan todos los atributos como se aprecia a continuación
UPDATE "mycars_person" SET "name" = \'jacob\', "last_name" = NULL, "age" = NULL WHERE "mycars_person"."id" = 1inicialmente podría pensarse que el rendimiento no afecte demasiado pero si se están actualizando grandes cantidades de información el rendimiento si se notara, por otro lado un truco bastante interesante es cuando se requiere actualizar un campo que puede ser calculado, para ello para no actualizar registro por registro si no hacer una actualización masiva se puede utilizar el siguiente código
from mycars.models import Person
from django.db.models import F
data = Person.objects.filter(id__gte=1, id__lte=20)
data.update(name=F('name')+'s')
y la consulta SQL que se ejecutaría sería la siguiente
UPDATE "mycars_person" SET "name" = ("mycars_person"."name" + \'s\') WHERE ("mycars_person"."id" >= 1 AND "mycars_person"."id" <= 20El código anterior lo que permite lograr es agregarle a todos los registros del filtro obtenido una 's' al final del name, si no se hubiera hecho de esta forma se hubieran ejecutados más consultas y cargado mas información en memoria que es precisamente lo que evita la función F logrando así en la actualizacion obtener un mejor rendimiento
Medir y auditar
Es muy difícil mejorar lo que actualmente no se está auditando por ello quiero recomendar dos herramientas que permiten saber por debajo del ORM que está pasando
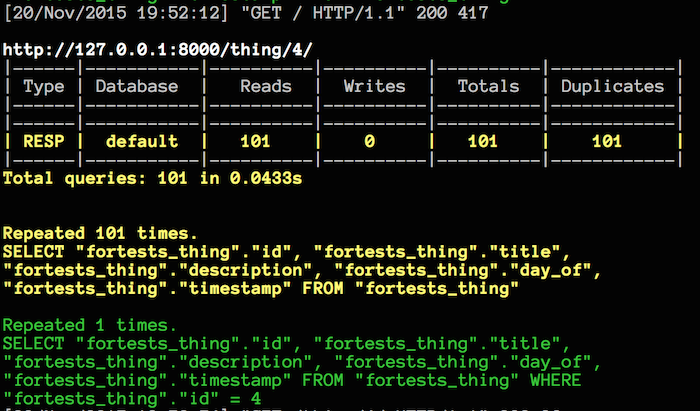
- Django Querycount es una herramienta que se adhiere a django con una instalación sencilla y configuracion tambien facil que permite mostrar las consultas y los tiempos que están tomando es super útil en desarrollo y además funciona cuando se trabaja con otros frameworks como django rest framework
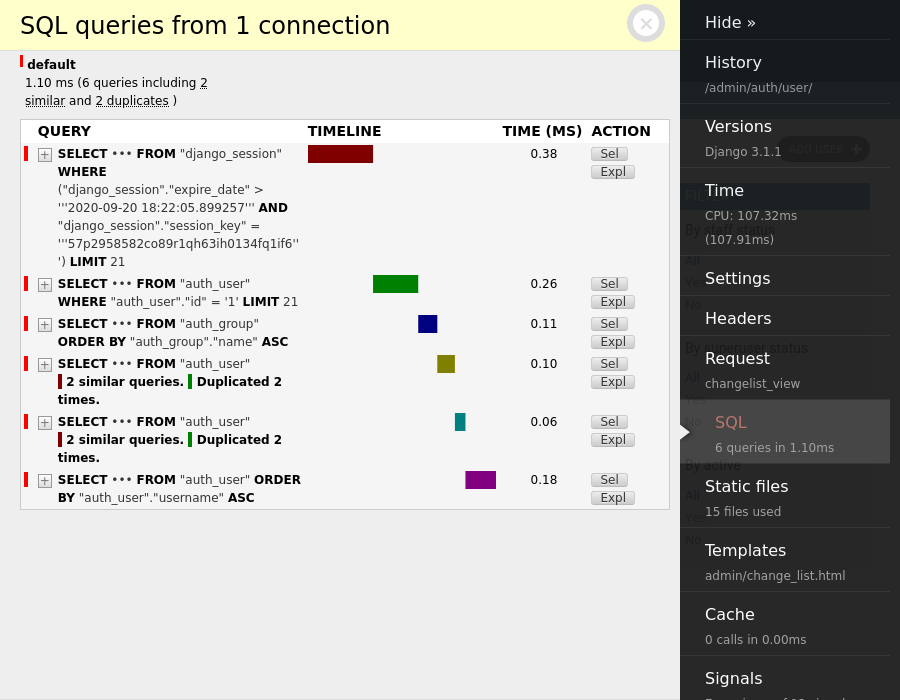
- Django Debug Toolbar es una herramienta que agrega un panel, personalmente yo la utilizo para auditar el django admin aunque funciona si se trabaja con render desde django
- Sin herramientas se pueden ver que consultas se han ejecutado a lo largo de lo que lleva el proyecto arriba utilizando el módulo connection nativo de django
from django.db import connection
print(connection.queries)Conclusión
Utilizar un ORM actualmente casi siempre es buena idea ya que cumplen con su función, son eficientes pero es importante entender que pasa por debajo, por que en proyectos en donde se sale del entorno de dev y entornos controlados normalmente se enfrentan con cargas de información masiva aqui el rendimiento juega un papel fundamental y designar a cada componente en este caso el gestor de base de datos a que haga su trabajo (que ya lo sabe hacer muy bien) es una estrategia que siempre ayudará