

I don't start to writing because I know all the answers, I start to writing because I know that I need to figure out the answers - Ilya Grigorik
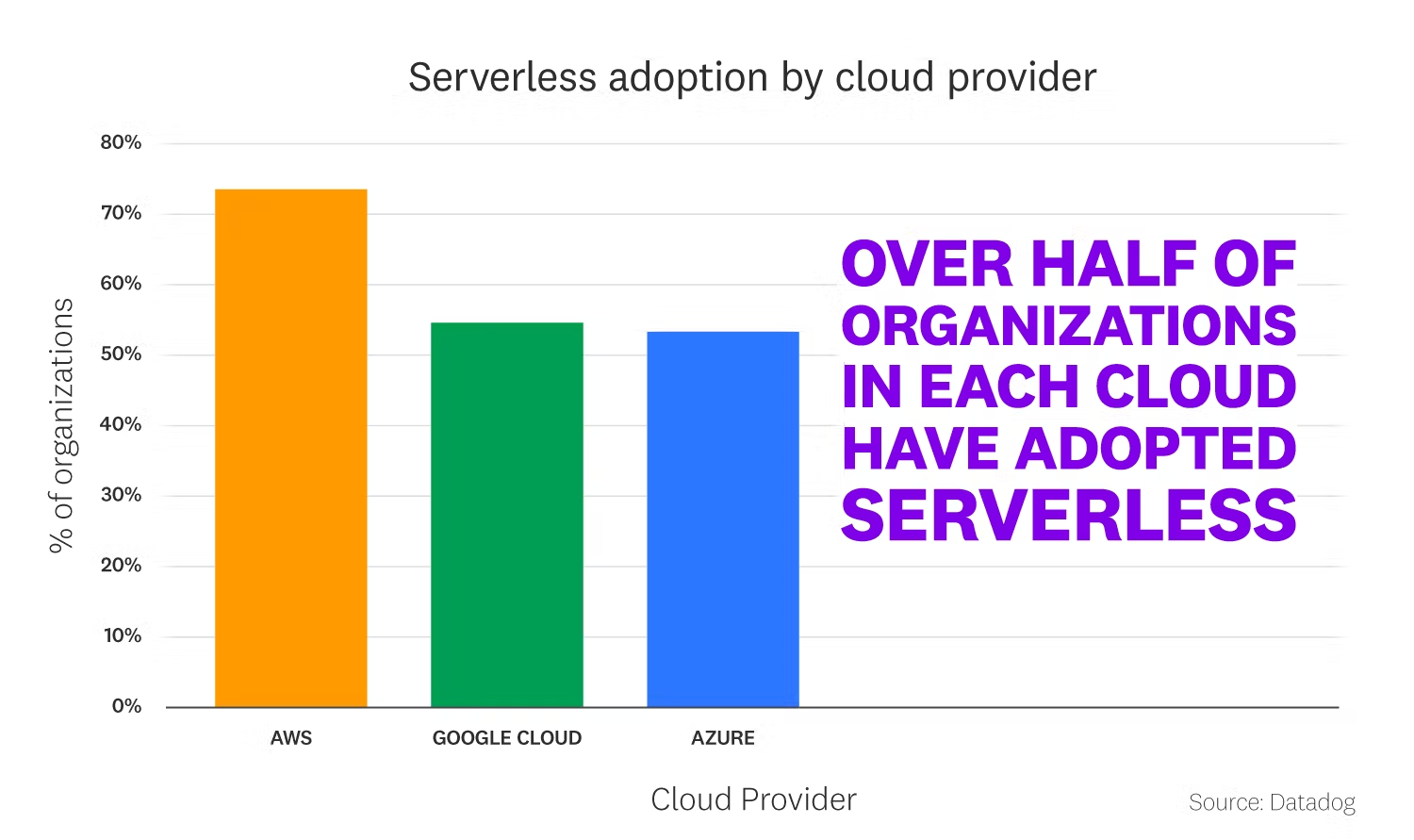
Serverless is a trend that has been growing in the last two years. Datadog shared state serverless study in 2020, this study showed the growth of serverless across different cloud providers, Show Figure 1.
Real definition of Serverless
Serverless has different definitions, for instance AWS has its definition and also Martin flower has another definition for serverless, these definitions are so accurate.
However, I prefer the definition described in the book called “Serverless an architecture on AWS”, where the author remarks the thought that serverless is more about “management less” using all the benefits of public cloud and cloud native.
Serverless first strategy?
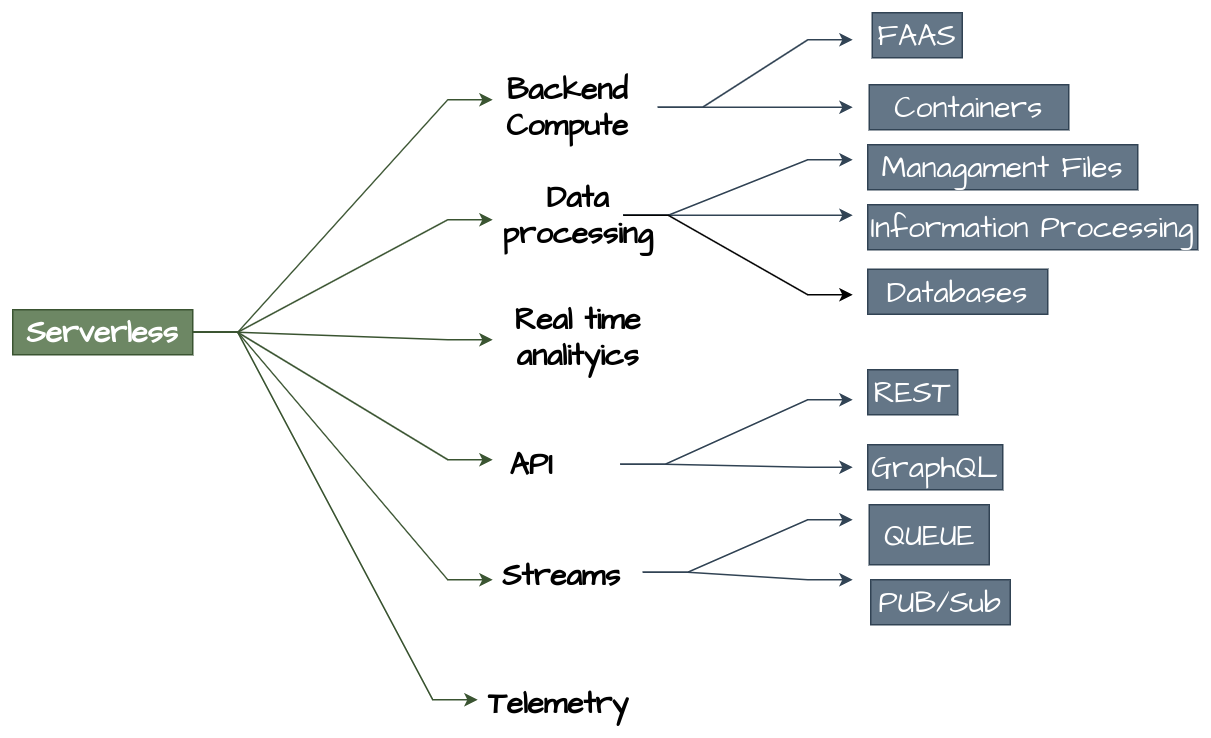
Serverless is a complete universe of different technologies, which means a lot of services classify in this category. A big mistake it is trying to compare serverless only to FaaS (function as a services) Show Figure 2. Therefore, it is important to answer the next question, how serverless technologies could be divided?

We can analyze serverless in two main levels
- Code, that is related with the business logic, libraries, and frameworks, in fact the code doesn't change a lot, in some cases the code need to add some lines of code to support different invocations
- Architecture, that focuses in the components and their interactions, the architecture level is the key when we use serverless, you can see some types of serverless technologies in the Figure 3
Over the last years I had to make different decisions about what technology o architecture I should implement, however decisions don't have to be either-or, with the correct strategies I could change the questions, and dilemmas to figure out better solutions.
Below I will share some takeaways using serverless architecture which could help you to understand if serverless architecture is the correct choice for you
Mindset
Serverless is a new way to build software, therefore coming with new strategies and new technologies, nevertheless the idea of abstraction should be kept, because at the end of the day serverless is one of many possible solutions.
In architecture, we talk about the big picture. This 'big picture' must be easy to understand for every architect, even if they do not know anything about the cloud provider. Having said that, the diagrams about the architecture should be draw in different levels, following the c4model. I always try to consider it in three levels.
- Solution level, it is only about abstractions (frequently I use c4model o another type of diagrams)
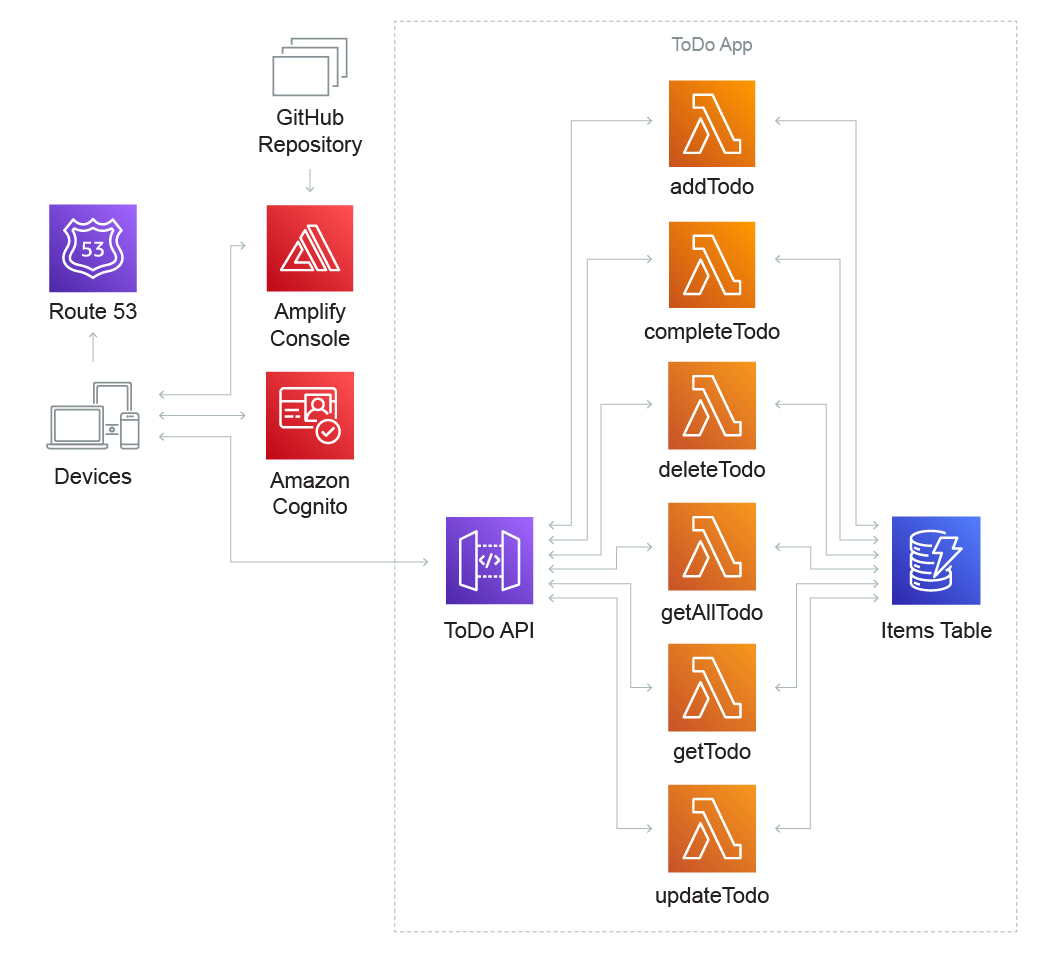
- Implementation level, it is when the cloud providers apear, Show Figure 3 in this level cloud provider names icons are used.
- Code level (structure of project), it is when the structure of the code is defined, the project structure should be related with the architecture.
A big advantage of drawing diagrams in different levels is that it become the final solution more understandable, because you can see different patterns that are implemented in each solution
Quickly is different to easy
With serverless You can jump in and prototype something quickly, but you’re gonna need to think about what does that mean to build a production application - Mike Roberts
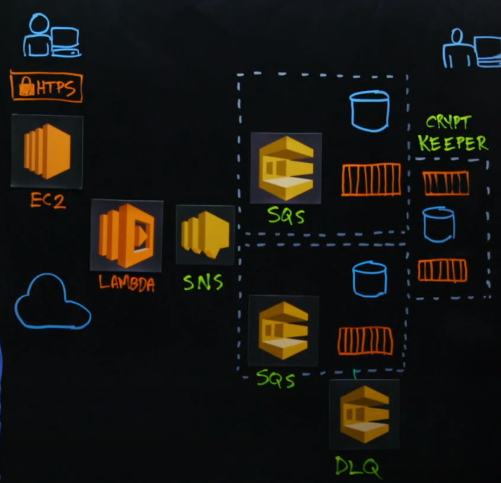
Less and complexity, are two words to remark, because these words make the base of serverless. For instance in AWS you have available interfaces to create a QUEUE connect with a lambda in minutes Show Figure 5.
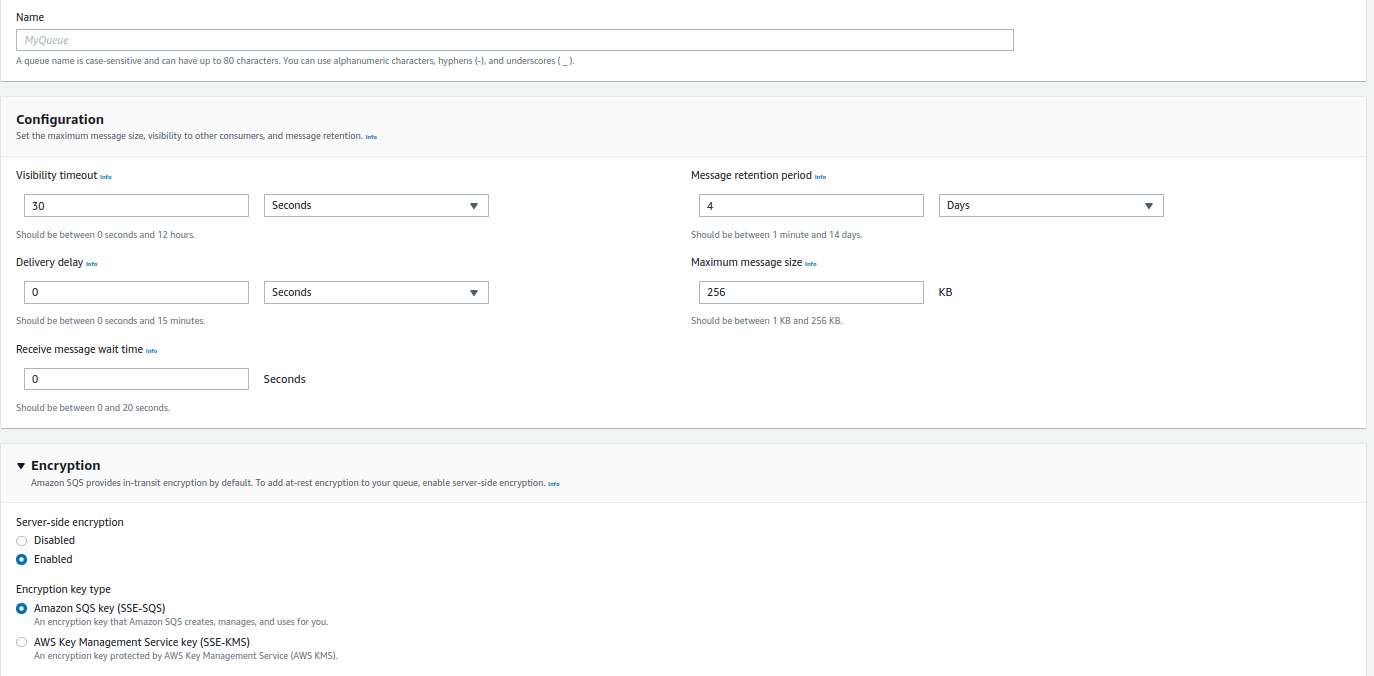
That is like magic, as you can see in the Figure 5 you don't need to struggle with complex configuration o technologies, nevertheless, starting with services only because seems easy to use it is not the better approach.
In order to avoid create a Frankenstein with a lot of services sticks around this I would like to give some questions that I try to answer before to decide which service to use
- is it the implementation necessary? Or is it only for trending?
- What is the price model?
- What other options could work well when the technology is not enough? Is it difficult to migrate to another technology?
- Are there libraries to support easy integration?
- Who is behind the stack? What patterns are implementing it?
- Trying to imagine some complex use case, is it possible to resolve it with serverless technology?
- What about documentation? Serverless is relatively new, and the documentation could be a challenging to find, it is basically about trying and learning from the errors.
Serverless partners
Serverless was not created to work only with another serverless services, In the real world the better solution is the hybrid architecture. For instance, a common use case it is tried to split a monolithic into microservices, Show Figure 6.
The last is MindTouch serverless architecture, which is an fascinating architecture because of its legacy component, which is connected with a new serverless architecture.
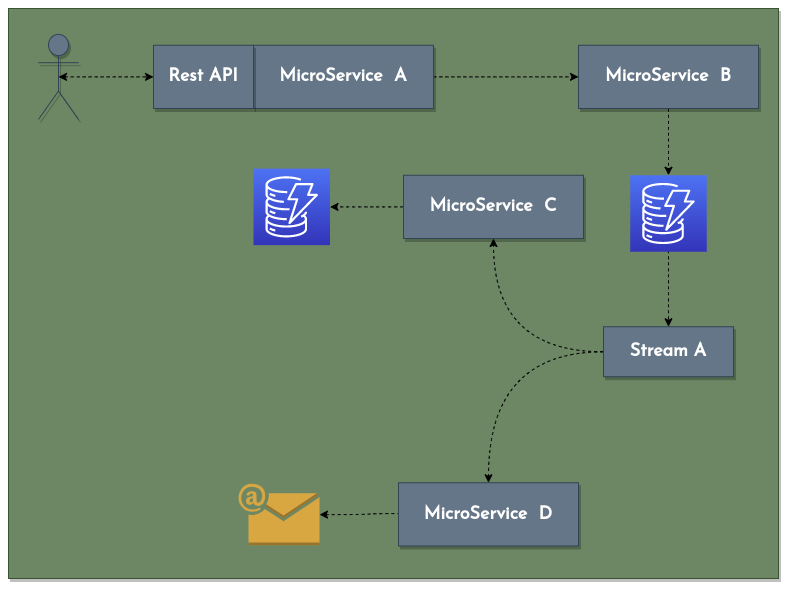
As you can see in the Figure 3 there is another example of the hybrid architecture (transactional+event driven). Therefore, using serverless architecture to potentiate a legacy system and develop new features around it, could be a good choice
Tools
As software developers, our work is to put things together and try to avoid reinventing the wheel. There are some tools o libraries that I consider useful if you are working with serverless:

- Serverless Framework: this is a complete framework to develop serverless architecture, serverless framework allows you to integrate with AWS and whole its ecosystem. Serverless framework use a powerful CLI, basing its configuration on YAML files. In addition, serverless abstract complexity allowing developers to be more productive.
- CDK: This is a framework which allows you to write code as infrastructure the main different with common frameworks it doesn't use YAML instead it uses languages such as python, go, and typescript indeed you can write lambdas functions and different serverless architectures
- AWS Lambda Powertools: These are a couple of libraries that could help you to write lambdas functions in python, for instance the middleware factory is a library which can execute code in different moments: before the lambdas is invoked, after the lambda is invoked and when some exceptions are generated
- MiddyJS: This is a simple but incredible library that allows you to create middleware using the express style. Re-use of code is a significant part of best practices in software development.
- typedi: This is a light tool to work with dependency injection in TS. With it, you can build well-structured and easily testable serverless applications.

- LocalStack: This is a framework to simulate different AWS services using Docker, it contains a useful CLI, which allow you running test without execute any deploys. There are two versions, standard and pro, the pro contains some advanced features but in general the standard is enough.
Observability
Observability is specially important in serverless because there are a lot of services working together at the same time, and it is probably that something fails. Effective monitoring is not only about logs, it is a complete strategy, and I would like to remark three points.
- Metrics
- Logs
- Distributed tracing
Each cloud provider has its own tools or services to implement observability, however in some cases that couldn't be enough. Underneath, I'll show some tools that have been useful for me.
- Datadog: Datadog is a complete platform for monitoring cloud services and serverless applications, in addition Datadog come with an intuitive platform which you can create different dashboards
- Lumigo: Lumigo is similar to Datadog, but the main different is that lumigo focuses on traceability. The more incredible feature it is the graphs and the following to the transaction to the time of live.
- ELK: ELK stack are three main technologies Elastisearch, Kibana, and Logstash they are powerful tools to implement an observability solution, the only inconvenient could be that ELK is a general solution, if you want to use in serverless you need to adapt the solution
- Grafana + Prometheus: That stack is similar to ELK, Grafana is a tool to create dashboard and Promethus have the responsibility to recollect logs and expose information using a query language called PromQL, in the same way that ELK that stack is not focuses on serverless, but that can be adapted
Software engineering is always a game of tradeoffs, hence the correct tool always depends on the context which could be related with money, libraries, experience, etc. In my perspective the tool is not the more essential thing, the deal is that whatever solution you decided should allow you centralized logs, metrics, traceability, and dashboards.
Mentions
Thanks to Jeisson Rangel for reading drafts and give me feedback of this