

Hace un tiempo he venido trabajando con serverless y esto ha sido todo un reto, el tener que pensar primero en microservicios, lambdas y eventos es todo un proceso, sobre todo cuando vienes de trabajar con first think monolith Ver Figura 1, pensar en serverless es pensar en responsabilidades individuales, en dividir el trabajo los mas detallado posible, en orquestar, en integrar, en continuos delivery y continuos deployment, algo gracioso aquí es que en mi tesis leí varios artículos sobre estas dos estrategias pero hasta ahora he logrado entender cual es la diferencia entre las dos (y no me la pregunten por que me confundo tratando de explicarla)

Que he aprendido
En este articulo quiero enfocarme en tratar de explicar algunas cosas que he aprendido y que seguro te serán de ayuda ahorrándote tiempo, pues este enfoque es bastante nuevo, si bien hay mucho material getting started, no hay tanto material especializado, lo cual implica ser muy asertivos leyendo la documentación, por que en ese material en dos lineas pueden explicarte el por que del error que te sucede y no logras solucionar, sin mas preámbulo, veamos algunos de los aprendizajes
Dependencias dev != prod
Para manejar las dependencias en python se maneja el virtualenv utilizando un archivo sencillo requirements.txt para congelar las versiones de las librerias que se usaran, esto esta ok para algunas situaciones, pero definitivamente el manejo que se le da en NodeJS con npm es muchísimo mejor, en las lambdas se necesita pensar mucho en el espacio que ocupara el proyecto a desplegar, esto por que se tienen restricciones de espacio, en desarrollo se pueden requerir algunas dependencias que no necesariamente quieres subir a una lambda, un caso muy común es boto3 que es el SDK para conectarse a AWS, este ya esta incluido como layer y se puede utilizar sin comprimirlo dentro del codigo, por lo tanto subirlo es desperdiciar espacio, por ello una opcion que me ha funcionado es usar poetry, este es un gestor de paquetes que se podría comparar con npm lo interesante de poetry es que podemos tener configuraciones de desarrollo y de prod como se aprecia a continuación
[tool.poetry]
name = "MyProject"
version = "0.1.0"
description = ""
authors = ["Jairo Andres <Jairo>"]
[tool.poetry.dependencies]
python = "^3.8"
requests = "^2.26.0"
[tool.poetry.dev-dependencies]
pytest = "^6.2.5"
black = "^21.12b0"
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
build-backend = "poetry.core.masonry.api"
utilizando virtualenv tendríamos que generar un archivo como este
pytest==6.2.5
python-dateutil==2.8.2
requests==2.26.0
black==21.12b0en nuestro serverless de configracion tendríamos algo como el siguiente ejemplo
service: myproject
frameworkVersion: '2'
custom: ${file(../../serverless.common.yml):custom}
package:
individually: true
provider:
name: aws
runtime: python3.8
stage: dev
lambdaHashingVersion: 20201221
environment:
stage: ${self:custom.stage}
tableName: !ImportValue ${self:custom.sstApp}-TableName
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:DescribeTable
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource:
- !ImportValue ${self:custom.sstApp}-TableArn
functions:
auth:
handler: myfunction.create
events:
- http:
path: create
method: post
cors: true
plugins:
- serverless-python-requirements
el plugin de python-requirements se encarga automáticamente de detectar el archivo llamado pyproject.toml , con este archivo se generan los requirements, pero solo de producción, con esto no solo tenemos resuelto las dependencias, si no que tenemos un gestor de paquetes con muchas ventajas, también si quieres generar el requirements tu mismo puedes usar el siguiente comando
poetry export -f requirements.txt > requirements.txt --without-hashesGestionar la infraestructura aparte
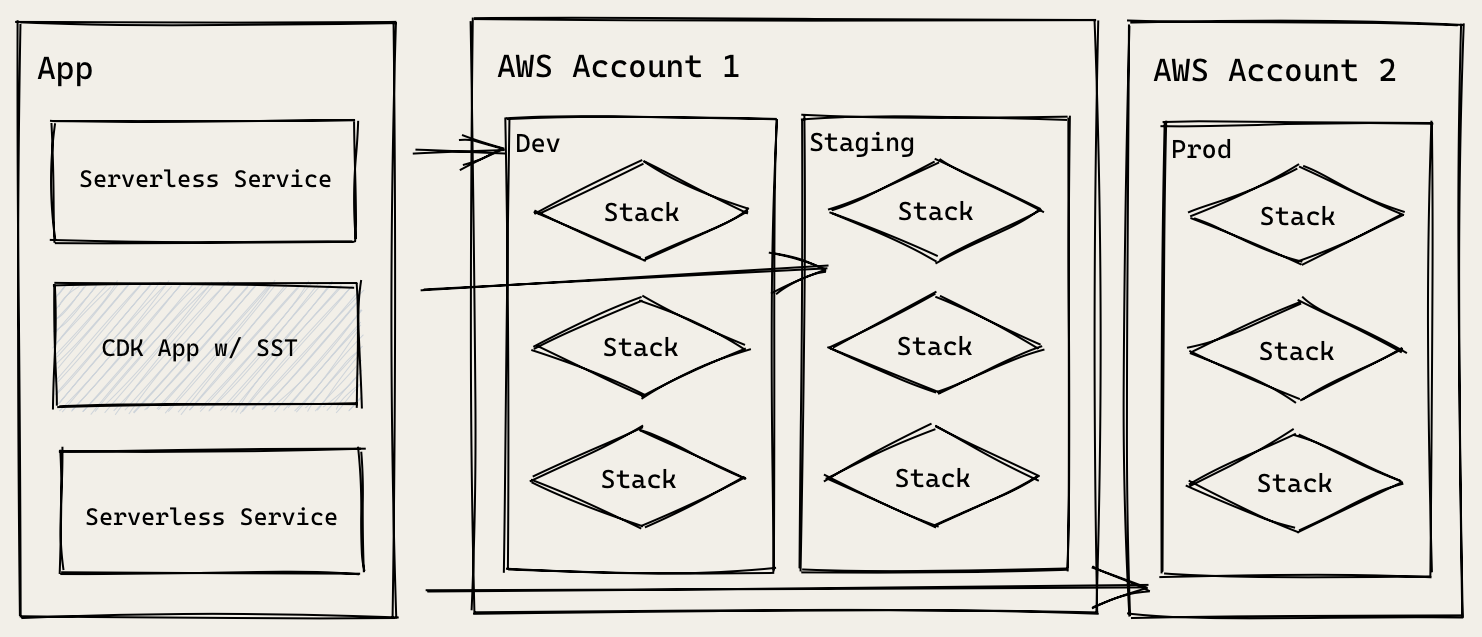
El archivo serverless.yml permite también crear recursos de AWS, esto quiere decir que dentro del ciclo de vida se conecta con cloudformation, por lo tanto toda la infraestructura se podría definir aquí, pero.. lo ideal es separar responsabilidades, si no nuestro código queda muy acoplado Ver Figura 2, una buena practica es usar aws cdk para definir todo lo relacionado a infraestructura y en serverless solo conectar con lo que se ha definido, en el siguiente ejemplo se puede apreciar mas claro
from aws_cdk import aws_dynamodb as _dynamodb, core
import os
class MyDynamodb(core.Stack):
def __init__(self, scope:core.Construct, id:str, **kwargs)->None:
self.context_app = "acquirers"
super().__init__(scope,id,**kwargs)
my_table = _dynamodb.Table(self,
os.getenv("STAGE")+"-"+"MyDynamoTable",
partition_key=_dynamodb.Attribute(
name="my_id", type=_dynamodb.AttributeType.STRING
))
core.CfnOutput(self, "TableName", value=my_table.table_name, export_name=f"{os.getenv('STAGE')}-{os.getenv('PREFIX_NAME')}-{self.context_app}-TableName")
core.CfnOutput(self, "TableArn", value=my_table.table_arn,
export_name=f"{os.getenv('STAGE')}-{os.getenv('PREFIX_NAME')}-{self.context_app}-TableArn")
service: myprojectbest
frameworkVersion: '2'
custom: ${file(../../serverless.common.yml):custom}
package:
individually: true
provider:
name: aws
runtime: python3.8
stage: dev
lambdaHashingVersion: 20201221
environment:
stage: ${self:custom.stage}
tableName: !ImportValue ${self:custom.sstApp}-TableName
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:DescribeTable
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource:
- !ImportValue ${self:custom.sstApp}-TableArn
functions:
auth:
handler: myfunction.create
events:
- http:
path: create
method: post
cors: true
plugins:
- serverless-python-requirements
Como pueden apreciar son dos proyectos diferentes, uno en CDK y otro en serverless pero se pueden conectar, una estrategia para hacerlo es usar el nombre del recurso (o aplicación) cargándolo desde variable de entorno como en el ejemplo anterior, de esta manera se puede referenciar el recurso, adicional a esto se puede agregar al nombre el ambiente por ejemplo my-dynamodb-dev de esta manera creas el recurso para diferentes ambientes, si trabajas con JS y TS puedes usar serverless-tack que es una librería que encapsula CDK pero que facilita la nomenclatura de los recursos, y de esta manera se pueden referenciar mas facil
Ordenar el repositorio
Cuando se empieza a trabajar con muchos servicios, estos deben quedar guardados en algún repositorio, si bien AWS tiene su herramienta para escribir código, esto claramente no se pude usar en un proyecto real, se debe utilizar algún repositorio de código, aquí es donde entra como se estructura ese repositorio o esos repositorios dependiendo de la estrategia a usar, una estrategia recomendable para comenzar es el monorepo, esta estrategia consiste en estructurar las lambdas dentro de un mismo proyecto, siguiendo una estructura como la siguiente
aws-serverless-ci-cd-demo
├── README.md
├── servicea
│ ├── handler.js
│ ├── package-lock.json
│ ├── package.json
│ └── serverless.yml
└── serviceb
├── handler.js
├── package-lock.json
├── package.json
└── serverless.ymlcada contexto tiene su propio serverless.yml , se puede tener un serverless.common.yml en el la carpeta raíz si estos archivos comparten algunas configuraciones, con esta estructura si por alguna razón se tienen dependencias compartidas fácilmente se crea una carpeta en el directorio raíz llamada libs y se importa en las lambdas que lo comparten, esto hará que en el despliegue esta carpeta lib se agregue a cada lambda, una configuración a tener en cuenta es la siguiente
service: myproject
package:
individually: true
individually permite desplegar cada proyecto por aparte, es decir empaqueta en el ejemplo anterior un zip para servicea y otro para serviceb, esta estrategia se puede conectar por ejemplo con el CI/CD de serverless que es un ambiente genial para gestionar estos despliegues, del cual hablaremos mas a detalle después, pero en resumen este servicio permite automatizar los flujos de despliegues y soporta monorepo, de esta manera solo despliegue los cambios en las lambdas en donde se realizo algún feature o fix y no en todas las lambdas
Serverless no es Architectureless
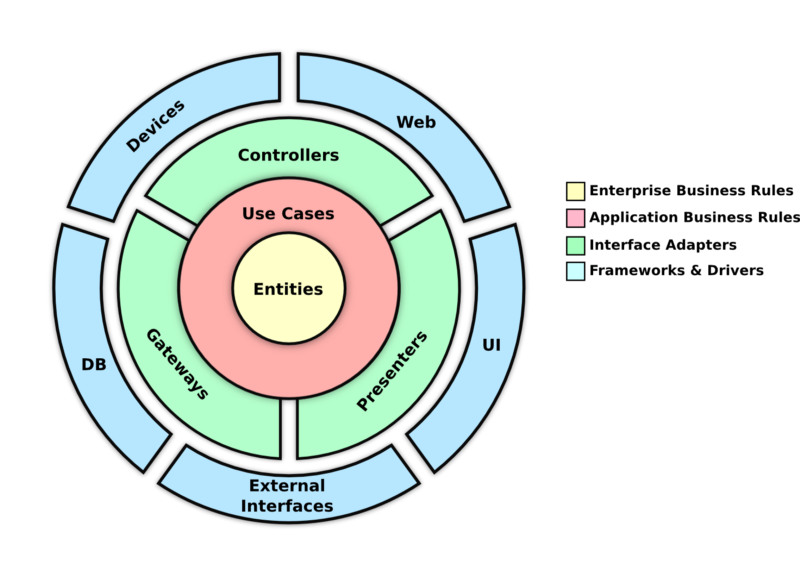
Cuando se trabaja con serverleess se debe pensar en funciones con tareas muy especificas, donde su procesamiento debe ser muy rápido y ademas deben ser livianas, cuando un proyecto se decide estructurar con lambdas y no solo son funciones sueltas, se debe pensar en una arquitectura la cual debe estar reflejada en su código, por que no quieres tener código suelto y tener ahora un espagueti pero dividido en cientos de funciones, una opción es en pensar en una arquitectura de referencia Ver Figura 3 e implementarla volviéndola un poco mas ligth, pero que respete sus principios y donde podamos usar cosas como inyección de dependencias, abstracciones etc, no hablo de convertir el microservicio en un monolito, mi idea es que lo poco que haga la función lo haga bien, pensando siempre en el microservicio "como un todo" que debe tener esa capacidad de sobrevivir por si mismo
Conclusiones
En lambdas y serverless están constantemente surgiendo mucho contenido, pero mi percepción es que aun estamos muy nuevos con esta tecnología y nos falta todavía descubrir mas sobre ella, encontrar mas errores, publicarlos en starckoverflow y generar esa experiencia que generalmente facilita la vida a los desarrolladores, ahorita no existe esa experiencia, por lo que se pueden encontrar varios stoppers durante su implementacion, pero entender que serverless no busca ir en contra del conocimiento de software que ya tenemos es fundamental para que los proyectos sigan buenas practicas.
Publicidad no paga
Ya esta llegando el fin de este año, e inicialmente inicie un reto personal el cual consistia en escribir un post semanalmente, ya quedan unas pocas semanas , por eso si quieres que escriba sobre algun tema, o si algun articulo mio te ha podido ayudar o te ha servido, sientanse libres de escribirme en cualquiera de mis redes sociales , y para compartirme sus apreciaciones