
Los type annotations son una caracteristica bastante interesante agregada en python apartir de la version 3.5, la cual nos permite agregar tipos de datos tanto como a funciones, clases y variables estos tipos de datos no afectan el rendimiento y son muy usados junto con otras herramientas de validacion como mypy.
A la hora de desarrollar proyectos en python enfocados al scripting utilizar el tipado dinamico es un gran ventaja y esta bien, pero en proyectos grandes en donde existen validaciones, logica de negocio, casos de uso y mucho codigo modificado por diferentes programadores empieza a tonarse dificil entender que recibe una fucnion, que retorna una funcion etc, por eso estas caracteristicas en grandes proyectos son muy importantes veamos un ejemplo en codigo:
def greeting(name: str) -> str:
return 'Hello ' + nameEn la funcion anterior estamos especificando que la funcion greeting recibe un parametro string y esto retorna una concatenacion, esto esta muy bien por que ademas en visual studio code y otros editores agregan autocomplete a estas funciones y variables, esto funciona igual para cualquier tipo de dato de python como puede ser bool, int, float,date,list,dict (list y dict fueron agregados recientemente para usarse sin ninguna herramienta adicional en python 3.9) ok ahora veamos un ejemplo en donde no estariamos usando del todo bien esta caracteristica
Tendremos una archivo llamado persona.json para este caso pero puede ser una llamada a una API en donde devuelva el json como se muestra acontinuacion
{
"name":"Pedro Jose",
"age":20,
"birthday":"2000-11-09"
}Para cargar esta informacion realizamos el siguiente codigo en python (para los ejemplos de codigo usare python 3.7)
import json
persona = {}
with open("persona.json") as persona_json:
persona = json.load(persona_json)En el codigo anterior abrimos el archivo persona.json lo cargamos utilizando la libreria json a memoria y esto lo convierte a un diccionario, este codigo es un codigo comun usado en python con su tipado dinamico, pero ahora tranformaremos ese mismo codigo utilizando type annotations y nos quedaria de la siguiente forma
import json
from typing import Dict
persona:Dict = {}
def open_persona_file()->Dict:
with open("persona.json") as persona_json:
result_persona = json.load(persona_json)
return result_persona
persona = open_persona_file()En este caso si yo quisiera acceder a un dato del diccionario que me retorna esta funcion open_persona_file() lo accederia de la siguiente manera
persona["name"]
persona["age"]
persona["birthday"]Este codigo no esta mal, por que de alguna manera se esta segmentando el tipo de dato que retorna, ya sabemos que es un diccionario y tenemos todas sus propiedades y metodos disponibles para usar, el "problema" viene cuando no se pueden ver que atributos contiene este diccionario, suponiendo por ejemplo que ya no es un archivo que se puede abrir si no una API de un tercero (suponiendo que esta mal documentada, y en codigo tampoco quedaron los campos que se reciben) en este caso si bien se usa las annotations no se estan usando de la mejor manera, lo ideal para tambien estar en este concepto del "autodocumentado del codigo" podriamos hacer la siguiente modificacion
import json
from datetime import date
from typing import Dict
from pydantic import BaseModel
class Persona(BaseModel):
name:str
age:int
birthday:date
persona:Persona
def open_persona_file()->Persona:
with open("persona.json") as persona_json:
result_persona = Persona(**json.load(persona_json))
return result_persona
persona = open_persona_file()
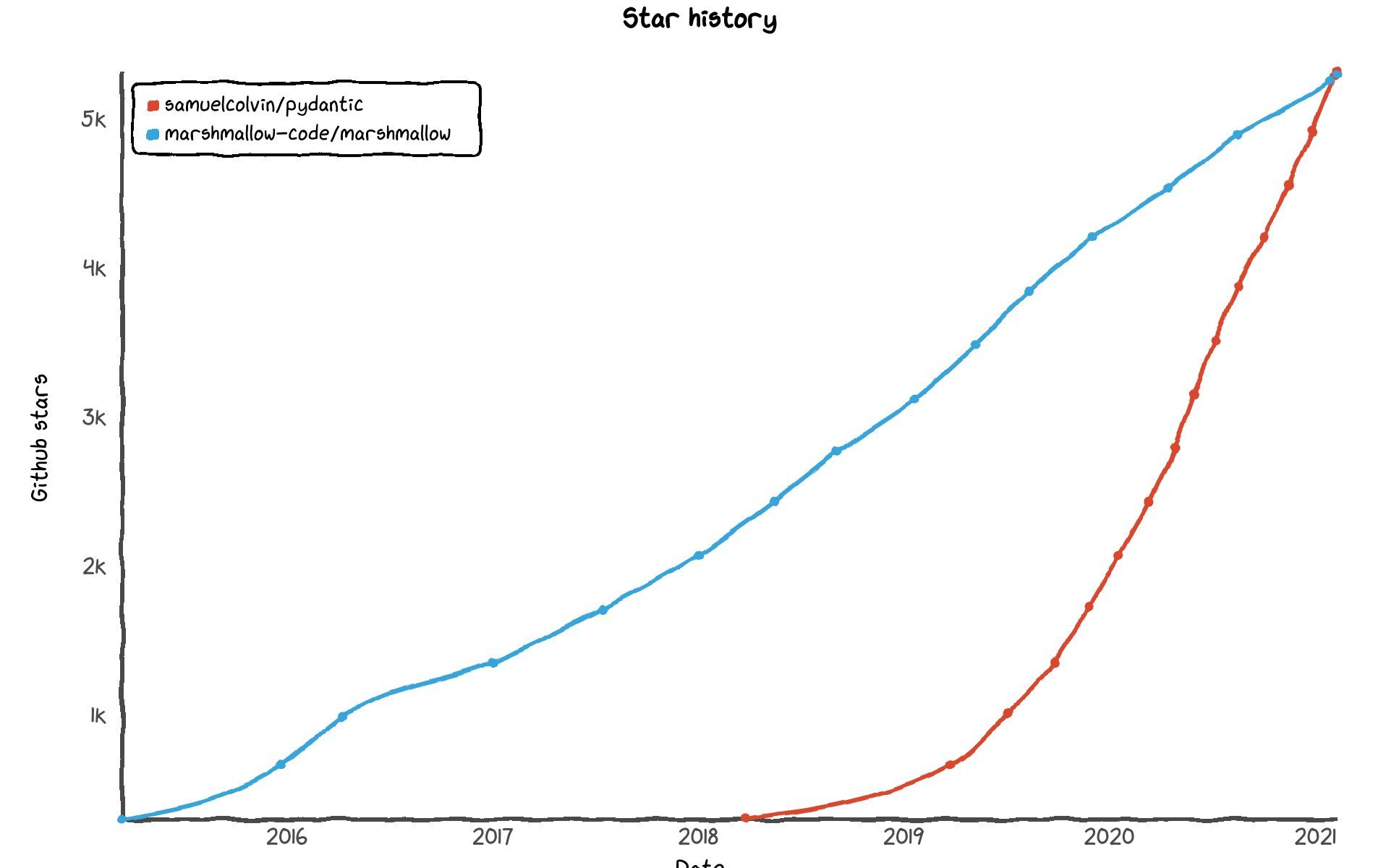
En este caso he agregado una libreria adicional conocida como pydantic es una libreria que ayuda a la validacion y complementa el uso de las type notations, y que porcierto recientemente supero en estrellas de github a su competencia mas cercana
siguiendo con el codigo en este caso se crea una clase llamada Persona la cual contiene los atributos que retorna el archivo .json (autodocumentacion de codigo) luego de esto se cambia el tipo de dato que retorna de tipo Dict a tipo de clase Persona como se aprecia en el siguiente segmento de codigo
def open_persona_file()->Dict: #antigua
def open_persona_file()->Persona: #nuevadentro del metodo se carga el json pero ya no se retorna el archivo cargado si no se utiliza para crear un objeto de tipo Persona, ya que pydantic permite la creaccion de objetos apartir de diccionarios, este automaticamente realiza tambien validaciones y conversiones en este caso convierte el atributo birthday a tipo date
result_persona = Persona(**json.load(persona_json))con estos cambios realizados, ahora para acceder a los atributos del archivo .json seria algo como esto
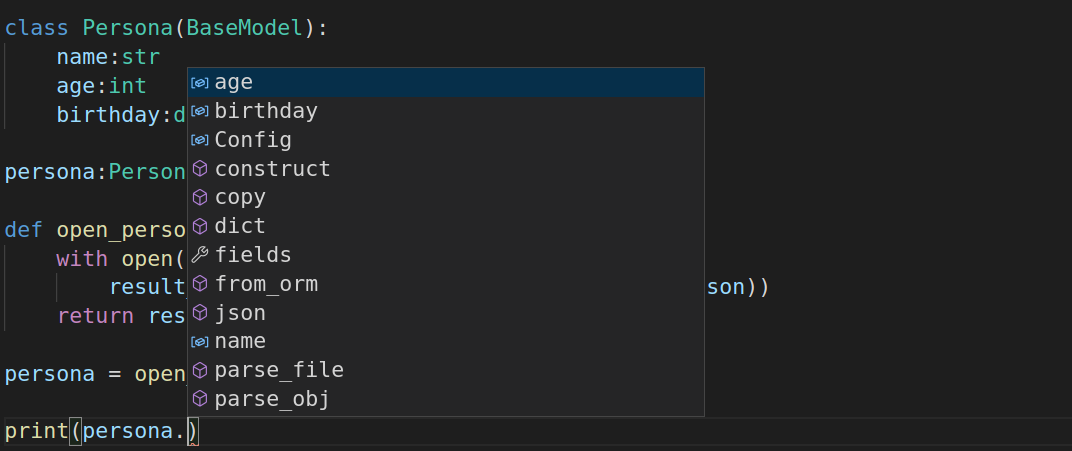
persona.name
persona.age
persona.birthdaypero lo mas interesante es el autocompletar que nos ahorra entre muchos posibles erorres digitar mal el atributo, poner un atributo que no existe o no saber que atributos contiene
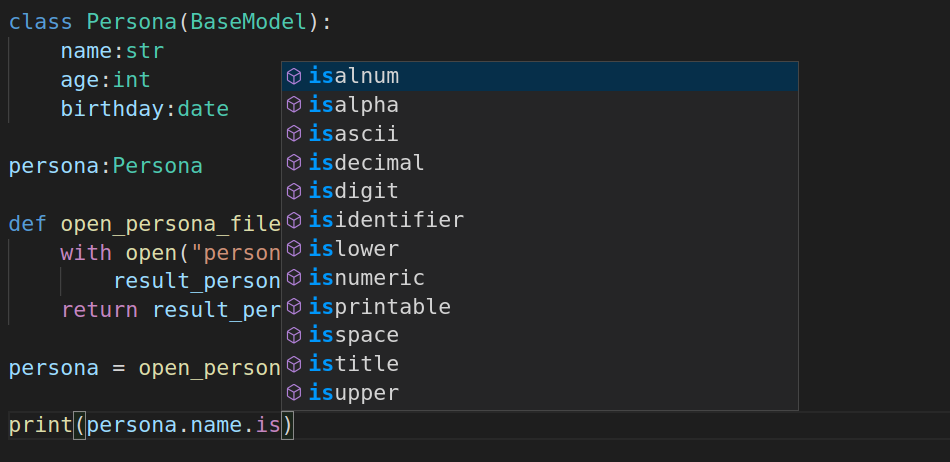
adicional al ver los atributos que contiene, podemos tambien tener autocompletado por cada atributo dependiendo del tipo que definimos, en este caso name al ser string tiene unos metodos propios que podemos ver acontinuacion
todo esto puede ser potenciado con librerias externas como por ejemplo mypy que ya mencione en el inicio del articulo, en general estas caracteristicas de python son muy buenas y a medida que las usemos de una mejor manera lograremos mayores beneficios.