

IBM Watson es un servicio de IA ofrecido por IBM Cloud, este servicio contiene una gama de subservicios que se ofrecen a partir de esta IA pre-entrenada , depronto algunos lo recuerdan del popular concurso de jeopardy donde la IA de IBM salió vencedor y demostró la capacidad que tenía para el entendimiento del lenguaje natural (se aprecia en el video a continuación) toda esta IA fue llevada a la nube y ofrecida por medio de servicios
Uno de estos servicios se llama Natural Language Analyze el cual permite realizar análisis de textos escritos en diferentes lenguajes y a partir de estos texto procesar y obtener diferentes resultados dependiendo de qué parámetros se envían, en este artículo nos enfocaremos en este sub-servicio donde procesaremos tweets y obtendremos diferentes clasificaciones
Antes de empezar a hablar de IBM Cloud este artículo sigue la "metodología" que venía trabajando y actualmente nos ubicamos en la etapa de procesamiento en nube como se aprecia en la Figura 1, con esta etapa finaliza el proceso y al final del artículo se dejará la implementación total del código como resultado final
IBM Cloud como la gran mayoría de nubes públicas tiene su API la cual permite acceder a diferentes servicios para este caso se usará un SDK o wrapper de esta API, pero no es necesario trabajar con python de hecho simplemente con curl se podría utilizar, sin más pasemos al código

Código
Antes de empezar necesitaremos instalar el SDK llamado ibm-watson adicional instalare python-dotenv, este SDK funciona con version de python 3.5 o superiores para mi caso utilizare python 3.8 y poetry como gestor de dependencias
poetry add ibm-watson python-dotenvEmpezare con un ejemplo sencillo procesando un texto simple y ver que información podemos obtener, en este caso se va a analizar en función del sentimiento que expresa el texto, IBM Watson permite analizar un texto y definir si este texto tiene una intención positiva, negativa o neutra basada en una calificación que va desde -1 se interpreta como negativa 0 como neutra y 1 como una intención positiva como se observa en el código.
import os
from ibm_watson import NaturalLanguageUnderstandingV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from ibm_watson.natural_language_understanding_v1 import (
Features,
KeywordsOptions,
SentimentOptions,
ConceptsOptions,
)
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
API_KEY = os.getenv("API_KEY")
URL_SERVICE = os.getenv("URL_SERVICE")
def analyze_text(text: str):
auth = IAMAuthenticator(apikey=API_KEY)
natural_language = NaturalLanguageUnderstandingV1(
version="2020-08-01", authenticator=auth
)
natural_language.set_service_url(URL_SERVICE)
return natural_language.analyze(
text=text,
features=Features(
sentiment=SentimentOptions(),
keywords=KeywordsOptions(),
concepts=ConceptsOptions(),
),
).get_result()
response = analyze_text(
"Criterion restaurant is an excellent place to share with the family,"
"variety of dishes and very good service."
)
sentiment = response["sentiment"]["document"]
keywords = response["keywords"]
concepts = response["concepts"]
print(f"Lenguaje: {response['language']}")
print(
f"Sentimiento : {sentiment['label']} - Porcentaje: {float(sentiment['score'])*100}%"
)
print("")
print("Palabras claves del texto")
for keyword in keywords:
print(
f"Texto : {keyword['text']} - Relevancia: {float(keyword['relevance'])*100}% "
)
print("")
print("Conceptos claves del texto")
for concept in concepts:
print(f"Concepto: {concept['text']} - Mas info: {concept['dbpedia_resource']}")Se ejecuta el código y vemos la salida en pantalla
poetry run main.pyLenguaje: en
Sentimiento : positive - Porcentaje: 99.0506%
Palabras claves del texto
Texto : Criterion restaurant - Relevancia: 99.5333%
Texto : excellent place - Relevancia: 98.9707%
Texto : good service - Relevancia: 85.256%
Texto : family - Relevancia: 61.8372%
Texto : variety of dishes - Relevancia: 24.8506%
Conceptos claves del texto
Concepto: Service - Mas info: http://dbpedia.org/resource/Service_(economics)
Para este ejemplo he simulado un comentario de un restaurante, en consola hay una salida que que dice algunas cosas importantes, pero antes explicaré un poco el código, para ello nos centraremos en la función analyze_text()
def analyze_text(text: str):
auth = IAMAuthenticator(apikey=API_KEY)
natural_language = NaturalLanguageUnderstandingV1(
version="2020-08-01", authenticator=auth
)
natural_language.set_service_url(URL_SERVICE)
return natural_language.analyze(
text=text,
features=Features(
sentiment=SentimentOptions(),
keywords=KeywordsOptions(),
concepts=ConceptsOptions(),
),
).get_result()Lo primero que se debe hacer es utilizar un objeto de IAMAuthenticator, este objeto básicamente permite realizar llamados a la API agregando el token, luego de ello se debe generar un objeto de la clase NaturalLanguageUnderstandingV1 recibiendo como parámetros el objeto de IAMAuthenticator y la versión, que actualmente es 2020-08-01 Seguidamente se actualiza la url de nuestro servicio, esta url y token la podemos obtener accediendo a nuestra cuenta de IBM Cloud como se muestra en la Figura 2
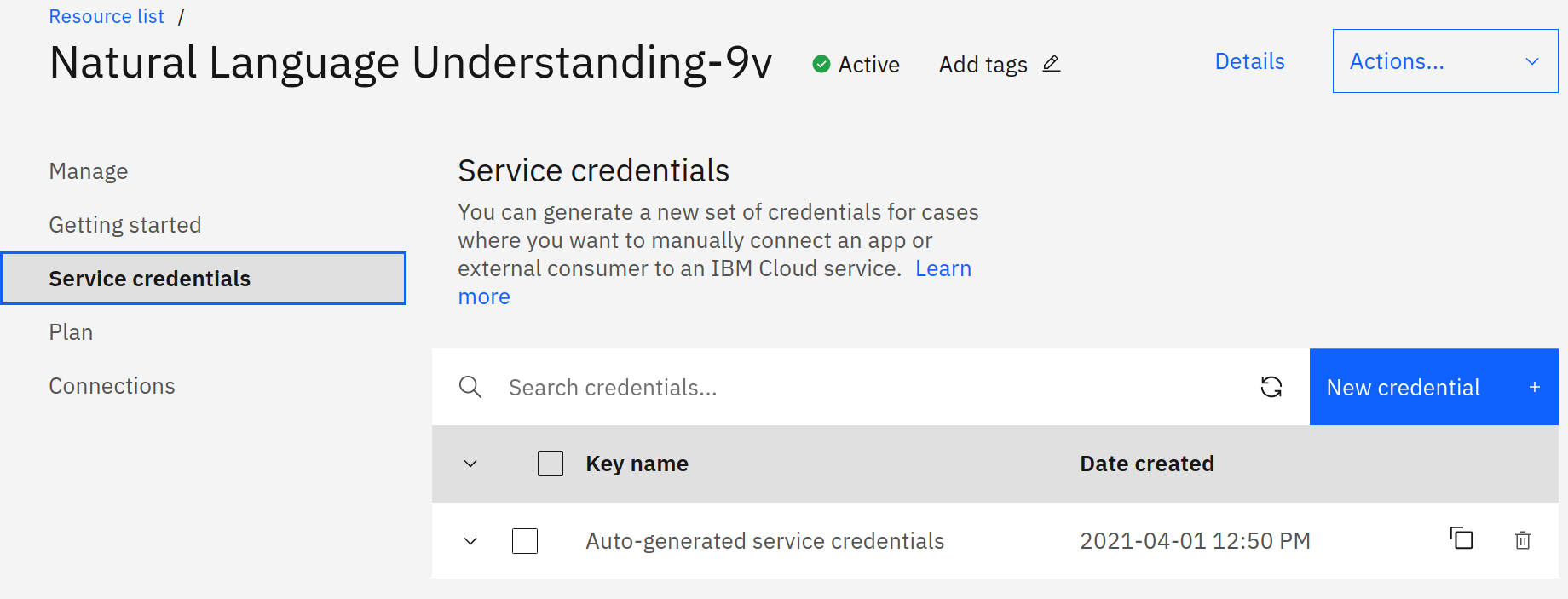
Luego de ello se llama al método analyze() este recibe los siguientes parámetros
- text el texto en plano que se quiere analizar, este parámetro puede variar ya que el servicio permite analizar html y urls como se muestra aquí
- features son características o filtros que se quiere que IBM Watson procese, ya que por defecto se procesa lo básico, en este caso le estamos pasando tres parámetros:
- sentiment este parámetro lo que le dice a IBM Watson es que basado en su entreamiento previo analize el texto en general y lo clasifique con una intención negativa, neutra o positiva
- keywords le dice a IBM Watson que basado en el procesamiento del lenguaje natural busque dentro del texto palabras que son relevantes en el contexto
- concepts identifica los temas generales del texto definiéndolo con una palabra que no necesariamente esta palabra debe encontrarse dentro del texto a analizar, adicional agrega un link en donde se define este concepto, esto suena un poco confuso pero un ejemplo podría ser un texto que esté hablando sobre procesamiento de lenguaje natural, un concepto podría ser linguist
Con esto ya se tiene un sin fin de posibilidades para procesar textos, para este procesamiento se usan modelos que han sido entrenados previamente, por tal motivo con lenguajes como el inglés funcionara mucho mejor que con el español ya que este tiene algunas limitaciones como se puede observar en la Figura 3
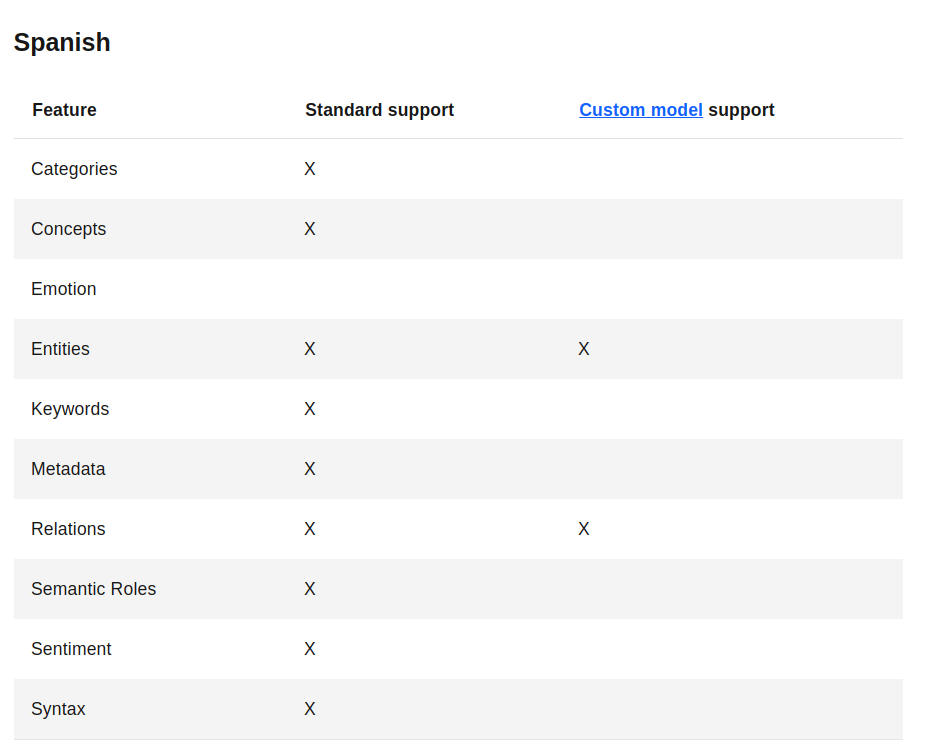
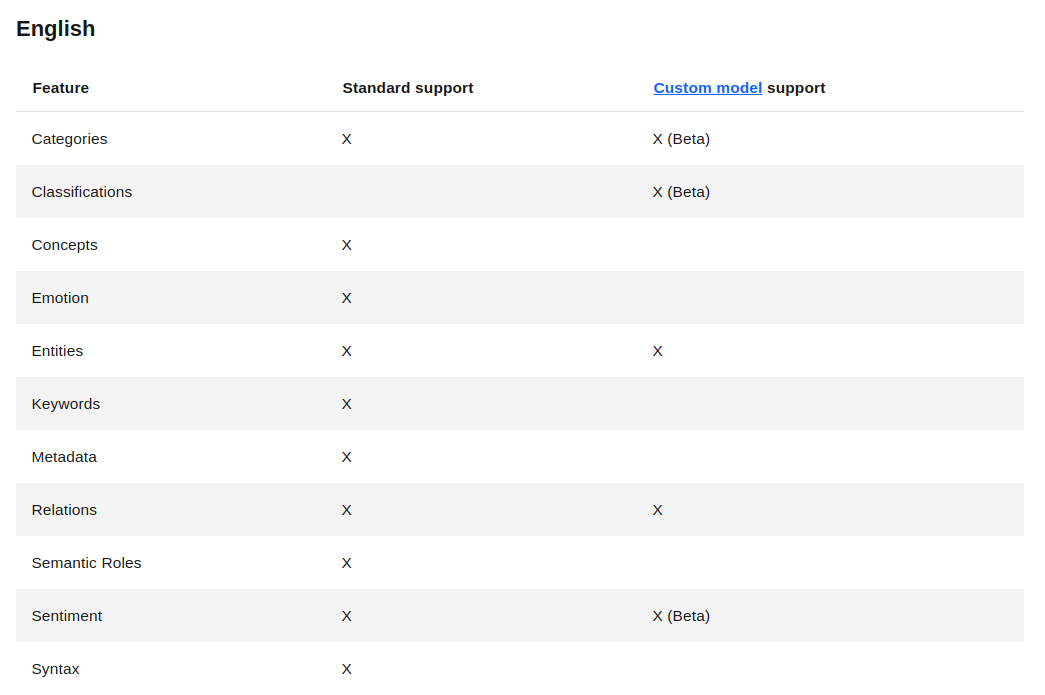
Como se observa estos son todas las funciones que se tienen disponibles tanto en inglés como en español, pero español no tiene una de las funciones más interesantes, el cual consiste en el análisis de emociones como se mostrará en el siguiente código donde se obtendrá más información
import os
from ibm_watson import NaturalLanguageUnderstandingV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from ibm_watson.natural_language_understanding_v1 import (
EmotionOptions,
Features,
KeywordsOptions,
SentimentOptions,
ConceptsOptions,
)
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
API_KEY = os.getenv("API_KEY")
URL_SERVICE = os.getenv("URL_SERVICE")
def analyze_text(text: str):
auth = IAMAuthenticator(apikey=API_KEY)
natural_language = NaturalLanguageUnderstandingV1(
version="2020-08-01", authenticator=auth
)
natural_language.set_service_url(URL_SERVICE)
return natural_language.analyze(
text=text,
features=Features(
sentiment=SentimentOptions(),
keywords=KeywordsOptions(sentiment=True, emotion=True),
concepts=ConceptsOptions(),
emotion=EmotionOptions(),
),
).get_result()
response = analyze_text(
"Criterion restaurant is an excellent place to share with the family,"
"variety of dishes and very good service."
)
sentiment = response["sentiment"]["document"]
keywords = response["keywords"]
concepts = response["concepts"]
emotions_text = response["emotion"]["document"]["emotion"]
print(f"Lenguaje: {response['language']}")
print(
f"Sentimiento : {sentiment['label']} - Porcentaje: {float(sentiment['score'])*100}%"
)
print("")
print("Palabras claves del texto")
count = 1
for keyword in keywords:
print(
f"#{count} {keyword['text']} - Relevancia: {float(keyword['relevance'])*100}% "
)
print("emociones por keyword:")
emotions_keywords = keyword["emotion"]
for emotion_key, emotion_value in emotions_keywords.items():
print(f"{emotion_key} con un porcentaje de {float(emotion_value)*100} %")
print("")
count += 1
print("")
print("Conceptos claves del texto")
for concept in concepts:
print(f"Concepto: {concept['text']} - Mas info: {concept['dbpedia_resource']}")
print("")
print("Emociones encontradas en el texto en general")
for emotion_key, emotion_value in emotions_text.items():
print(f"{emotion_key} con un porcentaje de {float(emotion_value)*100} %")Ejecutamos el código y vemos la salida de consola
poetry run main
Lenguaje: en
Sentimiento : positive - Porcentaje: 99.0506%
Palabras claves del texto
#1 Criterion restaurant - Relevancia: 99.5333%
emociones por keyword:
sadness con un porcentaje de 4.31 %
joy con un porcentaje de 81.0802 %
fear con un porcentaje de 0.3761 %
disgust con un porcentaje de 4.939 %
anger con un porcentaje de 1.0458 %
#2 excellent place - Relevancia: 98.9707%
emociones por keyword:
sadness con un porcentaje de 4.31 %
joy con un porcentaje de 81.0802 %
fear con un porcentaje de 0.3761 %
disgust con un porcentaje de 4.939 %
anger con un porcentaje de 1.0458 %
#3 good service - Relevancia: 85.256%
emociones por keyword:
sadness con un porcentaje de 4.31 %
joy con un porcentaje de 81.0802 %
fear con un porcentaje de 0.3761 %
disgust con un porcentaje de 4.939 %
anger con un porcentaje de 1.0458 %
#4 family - Relevancia: 61.8372%
emociones por keyword:
sadness con un porcentaje de 4.31 %
joy con un porcentaje de 81.0802 %
fear con un porcentaje de 0.3761 %
disgust con un porcentaje de 4.939 %
anger con un porcentaje de 1.0458 %
#5 variety of dishes - Relevancia: 24.8506%
emociones por keyword:
sadness con un porcentaje de 4.31 %
joy con un porcentaje de 81.0802 %
fear con un porcentaje de 0.3761 %
disgust con un porcentaje de 4.939 %
anger con un porcentaje de 1.0458 %
Conceptos claves del texto
Concepto: Service - Mas info: http://dbpedia.org/resource/Service_(economics)
Emociones encontradas en el texto en general
sadness con un porcentaje de 4.31 %
joy con un porcentaje de 81.0802 %
fear con un porcentaje de 0.3761 %
disgust con un porcentaje de 4.939 %
anger con un porcentaje de 1.0458 %
Como se puede observar la salida en consola tiene más información ahora, para el texto en general se tiene una nueva característica, se está analizando unas emociones con un porcentaje, en el caso del texto se detectó que la emoción joy tiene el mayor porcentaje 81%, esto es por que el comentario en el texto prevalece esta emoción, pero existe otra opción más cool todavia que se puede ver en la salida, se puede analizar la emoción de cada keyword encontrada en el texto es decir, en el contexto del texto en general se evalúa esa palabra clave y se calcula que emoción tiene, por ejemplo el keyword #1 Criterion restaurant en el contexto del texto la emoción con mayor porcentaje es joy esto debido a que el "comentario del restaurante" es positivo, listo voy a revisar lo nuevo que se agregó al código
def analyze_text(text: str):
auth = IAMAuthenticator(apikey=API_KEY)
natural_language = NaturalLanguageUnderstandingV1(
version="2020-08-01", authenticator=auth
)
natural_language.set_service_url(URL_SERVICE)
return natural_language.analyze(
text=text,
features=Features(
sentiment=SentimentOptions(),
keywords=KeywordsOptions(sentiment=True, emotion=True),
concepts=ConceptsOptions(),
emotion=EmotionOptions(),
),
).get_result()En el código se agregaron unos parámetros al método analyze(), a la clase KeywordsOptions se le agrego dos parámetros sentiment y emotion y se colocaron en True esto con el fin de que a cada keyword se le realice un procesamiento para encontrar el sentimiento y las emociones en el contexto del texto, además se agrego un nuevo parámetro
- emotion este parámetro analiza un texto o una palabra con las emociones disponibles en el servicio (sadness, joy, fear, disgust, anger) a cada emoción la etiqueta con un porcentaje
Este servicio es muy interesante pero lo bueno es que se puede mejorar realizando re-entrenamientos basados en el contexto de cada negocio ya que pueden existir algunos "issues" donde el modelo puede no funcionar del todo bien, o cómo debería funcionar por ejemplo
"La atención en el restaurante estuvo pésima, el parqueadero es inseguro y se demoró demasiado la atención, sin embargo la comida estuvo deliciosa"
este es un comentario común en un restaurante sin embargo el modelo lo clasifica como negativo, pero y si lo que se está buscando es saber si al comensal le gusto la comida independientemente del lugar? pues para estos casos especiales debe re-entrenarse el modelo y esto es muy fácil, como su documentación lo menciona consiste en sobrescribir unos formatos de csv y cargarlos a la plataforma, a partir de aquí se empieza el re-entrenamiento y el modelo final se usara para procesar los textos y palabras de nuestro negocio.
Conclusión
A manera de conclusión este servicio puede permitir ahorrar tiempo ya que no se debe tener conocimientos de machine learning ni altos conocimientos de NLP ni de análisis lingüísticos pues esto ya lo hace el servicio, no podría afirmar que es más económico ya que esto depende de cada problema y solucion, pero realizando una buena administración de los costos se puede obtener un buen precio y en caso de prototipos tenerlos funcionando en tiempos cortos y ya despues de tener luz verde para la implementación se podría buscar algo más elaborado.
El artículo no puede finalizar sin antes cerrar el ciclo de las publicaciones integrando y conectando los artículos anteriores para cargar, procesar, y analizar estos tweets a continuación dejo el código
import os
import tweepy
import spacy
from ibm_watson import NaturalLanguageUnderstandingV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from ibm_watson.natural_language_understanding_v1 import (
EmotionOptions,
Features,
KeywordsOptions,
SentimentOptions,
ConceptsOptions,
)
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
API_KEY = os.getenv("API_KEY")
URL_SERVICE = os.getenv("URL_SERVICE")
def convert_listwords_text(list_words):
text = ""
for word in list_words:
text = text + " " + word
return text
def get_atuh_tweepy():
auth_tweet = tweepy.OAuthHandler(
os.getenv("TWITTER_CONSUMERKEY"),
os.getenv("TWITTER_CONSUMER_SECRETKEY"),
)
auth_tweet.set_access_token(
os.getenv("TWITTER_ACESSTOKEN"), os.getenv("TWITTER_ACESS_TOKENSECRET")
)
return tweepy.API(auth_tweet)
def is_retweet(tweet):
return hasattr(tweet, "retweeted_status")
def get_tweets_by_query(query_search: str):
api_auth = get_atuh_tweepy()
parameters = {
"q": query_search,
"lang": "en",
"result_type": "mixed",
"tweet_mode": "extended",
}
count = 0
return tweepy.Cursor(api_auth.search, **parameters).items(1)
def analyze_text(text: str):
auth = IAMAuthenticator(apikey=API_KEY)
natural_language = NaturalLanguageUnderstandingV1(
version="2020-08-01", authenticator=auth
)
natural_language.set_service_url(URL_SERVICE)
return natural_language.analyze(
text=text,
features=Features(
sentiment=SentimentOptions(),
keywords=KeywordsOptions(sentiment=True, emotion=True),
concepts=ConceptsOptions(),
emotion=EmotionOptions(),
),
).get_result()
def clear_text():
nlp = spacy.load("en_core_web_sm")
tweets = get_tweets_by_query("covid")
docs = []
for position, tweet in enumerate(tweets):
doc = nlp(tweet.full_text)
docs.append(doc)
list_word = []
for token in doc:
if (
not token.is_punct
and not token.is_stop
and not token.like_url
and not token.is_space
and not token.pos_ == "CONJ"
):
list_word.append(token.lemma_)
text_analyze = convert_listwords_text(list_words=list_word)
response = analyze_text(
text=text_analyze
)
sentiment = response["sentiment"]["document"]
keywords = response["keywords"]
concepts = response["concepts"]
emotions_text = response["emotion"]["document"]["emotion"]
print("")
print(f"{text_analyze}")
print(f"Lenguaje: {response['language']}")
print(
f"Sentimiento : {sentiment['label']} - Porcentaje: {float(sentiment['score'])*100}%"
)
print("")
print("Palabras claves del texto")
count = 1
for keyword in keywords:
print(
f"#{count} {keyword['text']} - Relevancia: {float(keyword['relevance'])*100}% "
)
print("emociones por keyword:")
emotions_keywords = keyword["emotion"]
for emotion_key, emotion_value in emotions_keywords.items():
print(f"{emotion_key} con un porcentaje de {float(emotion_value)*100} %")
print("")
count += 1
print("")
print("Conceptos claves del texto")
for concept in concepts:
print(f"Concepto: {concept['text']} - Mas info: {concept['dbpedia_resource']}")
print("")
print("Emociones encontradas en el texto en general")
for emotion_key, emotion_value in emotions_text.items():
print(f"{emotion_key} con un porcentaje de {float(emotion_value)*100} %")
clear_text()
Ejecutamos y vemos el resultado en consola
poetry run python main.py hospital share info access care covid positive help share word 🙏 🏻
Lenguaje: en
Sentimiento : positive - Porcentaje: 69.258%
Palabras claves del texto
#1 positive help share word - Relevancia: 78.8031%
emociones por keyword:
sadness con un porcentaje de 14.564 %
joy con un porcentaje de 63.8976 %
fear con un porcentaje de 1.1111 %
disgust con un porcentaje de 2.946 %
anger con un porcentaje de 0.7223 %
#2 hospital share info access care covid - Relevancia: 21.1969%
emociones por keyword:
sadness con un porcentaje de 14.564 %
joy con un porcentaje de 63.8976 %
fear con un porcentaje de 1.1111 %
disgust con un porcentaje de 2.946 %
anger con un porcentaje de 0.7223 %
Conceptos claves del texto
Emociones encontradas en el texto en general
sadness con un porcentaje de 14.564 %
joy con un porcentaje de 63.8976 %
fear con un porcentaje de 1.1111 %
disgust con un porcentaje de 2.946 %
anger con un porcentaje de 0.7223 %