

Trabajar en desarrollo de software implica trabajar en diferentes ambientes, generalmente se trabaja con cuatro ambientes, el ambiente local, el ambiente dev, el ambiente stage y el ambiente de producción estos ambientes tienen diferentes variables de entorno lo que implica diferentes accesos a diferentes bases de datos y a los diferentes recursos que utiliza la aplicación (y es buena idea mantenerlo así ver Figura 1) en este artículo nos enfocaremos en el recurso base de datos.

La problemática
En el orm de django específicamente se trabaja con modelos y migraciones estos modelos son clases que se transforman en tablas de información, durante el ciclo de desarrollo es normal agregar cambios a estas clases agregando mas datos y mas información pero lo mas importante que puede ocurrir es que para que la aplicación funcione necesita una "pre-carga" de información o una información "semilla" la cual es una información que debe existir por defecto para que la aplicación funcione, veamos unos ejemplos
- Géneros, tipos de documentos o cualquier tipificación que implique el contexto de la aplicación
- Ciudades , departamentos y países
- Recursos , datos o bienes que deben de estar cargados previamente
en pruebas de integración también se podría necesitar cargar información semilla pero de datos generados randomicos, ese no es el enfoque de este post, en este post trataremos información semilla para el correcto funcionamiento de la aplicación en cualquier ambiente, en resumen la información semilla pone tu aplicación en un estado "ready-to-go". Bueno pasemos al código
Cargando información con django
django tiene dos métodos que nos permite cargar información el primero es utilizando data migrations y el segundo utilizando fixtures el primer método lo omitiré por que se limita mas a cargar información para testing, así que vayamos al segundo
lo primero es configurar nuestro ambiente, utilizare python 3.7 e instalare django y el controlador de mysql
pip install django mysqlclientcreamos el proyecto
django-admin startproject myprojectcreamos una app de prueba
django-admin startapp myappdespués de agregar la aplicación al config, y configurar los accesos a mysql creare en la aplicación un modelo llamado departamento y otro ciudad, creare un folder llamado fixtures que es donde django buscará la data a cargar y aquí creare un archivo en formato .json (django permite varios formatos entre ellos json y yaml) llamado mydata.json que contendrá las ciudades y departamentos a cargar como se aprecia a continuación
los modelos necesarios para guardar la información
from django.db import models
class Departamento(models.Model):
name = models.CharField(max_length=255)
class Ciudad(models.Model):
name = models.CharField(max_length=255)
departamento = models.ForeignKey(Departamento, on_delete=models.CASCADE)
el archivo mydata.json
[
{
"pk": 1,
"model": "myapp.departamento",
"fields": {
"name": "Amazonas"
}
},
{
"pk": 1,
"model": "myapp.ciudad",
"fields": {
"name": "Leticia",
"departamento": 1
}
},
{
"pk": 2,
"model": "myapp.ciudad",
"fields": {
"name": "Puerto Nari\u00f1o",
"departamento": 1
}
},
{
"pk": 2,
"model": "myapp.departamento",
"fields": {
"name": "Arauca"
}
},
{
"pk": 3,
"model": "myapp.ciudad",
"fields": {
"name": "Arauca",
"departamento": 2
}
},
{
"pk": 4,
"model": "myapp.ciudad",
"fields": {
"name": "Arauquita",
"departamento": 2
}
},
{
"pk": 5,
"model": "myapp.ciudad",
"fields": {
"name": "Cravo Norte",
"departamento": 2
}
},
{
"pk": 6,
"model": "myapp.ciudad",
"fields": {
"name": "Fortul",
"departamento": 2
}
},
{
"pk": 7,
"model": "myapp.ciudad",
"fields": {
"name": "Puerto Rond\u00f3n",
"departamento": 2
}
},
{
"pk": 8,
"model": "myapp.ciudad",
"fields": {
"name": "Saravena",
"departamento": 2
}
},
{
"pk": 9,
"model": "myapp.ciudad",
"fields": {
"name": "Tame",
"departamento": 2
}
}
]
luego de ello ejecutamos el comando
python manage.py loaddata mydatay obtenemos el siguiente resultado visto desde el django admin

para repasar lo que hicimos vamos a empezar por el archivo mydata.json este archivo contiene una estructura de la información que se planea guardar en formato json pero esta estructura es una estructura definida por django
{
"pk": "es el identificador",
"model":"el nombre del modelo en lowercase y la app a la que pertenece",
"fields": "sus atributos"
}las llaves foráneas se referencian utilizando el pk que se dio a cada objeto que se va a crear, django internamente carga de manera desordenada la información pero cuando hay referencias se gestionan para que se cargue primero la información de la que se dependa, con esta estructura ejecute el comando loaddata y le pase como parametro el nombre del archivo, django buscará en las carpetas fixutres todos los archivos que lleven este nombre, pueden existir en varios formatos, lo que hará django es ejecutar cada uno y volver a cargar la informacion, esto es importante por que si en un despliegue se agrega este comando y la información ya existe, django la borrara y la volverá a cargar eliminado los cambios realizados
Ami personalmente adaptarme al formato definido me parece que puede jugar en contra, por ejemplo este archivo de ciudades de colombia lo encontré en este repositorio y para adaptarlo al formato puede tomar bastante tiempo
Cargando la información fuera de django
En este apartado realizaré la carga pero utilizando mi propio script, esto quizás permita un poco más de libertad en cuanto a la lectura de información y el estándar que define django, sin embargo creo firmemente que es mejor un estándar que una preferencia individual (esto lo vi en un tweet que me llamo la atencion)
Utilizaremos el mismo proyecto y el mismo código, me descargare las ciudades de colombia registradas en este repositorio y las agregare al inicio del proyecto, adicional agregare al folder myapp una carpeta llamada seeds y agregare dentro de la carpeta un archivo llamado departamento.py con el siguiente código
import json
from myapp.models import Departamento, Ciudad
class DepartamentoSeed:
def __init__(self) -> None:
with open("departamentos.json", encoding="utf8") as data:
self.departamentos = json.load(data)
def should_run(self):
return Departamento.objects.count() == 0
def run(self):
for departamento in self.departamentos:
departamento_model = Departamento(name=departamento["departamento"])
departamento_model.save()
ciudades = departamento["ciudades"]
for ciudad in ciudades:
ciudad_model = Ciudad(name=ciudad, departamento=departamento_model)
ciudad_model.save()
y finalmente agregamos en el directorio raíz del proyecto un archivo llamado seed.py con el siguiente codigo
import os
import django
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
os.environ["DJANGO_SETTINGS_MODULE"] = "myproject.settings"
django.setup()
from myapp.seeds.departamento import DepartamentoSeed
def execute_seed():
departamento_seed = DepartamentoSeed()
if departamento_seed.should_run():
departamento_seed.run()
execute_seed()y lo ejecutamos utilizando el siguiente comando
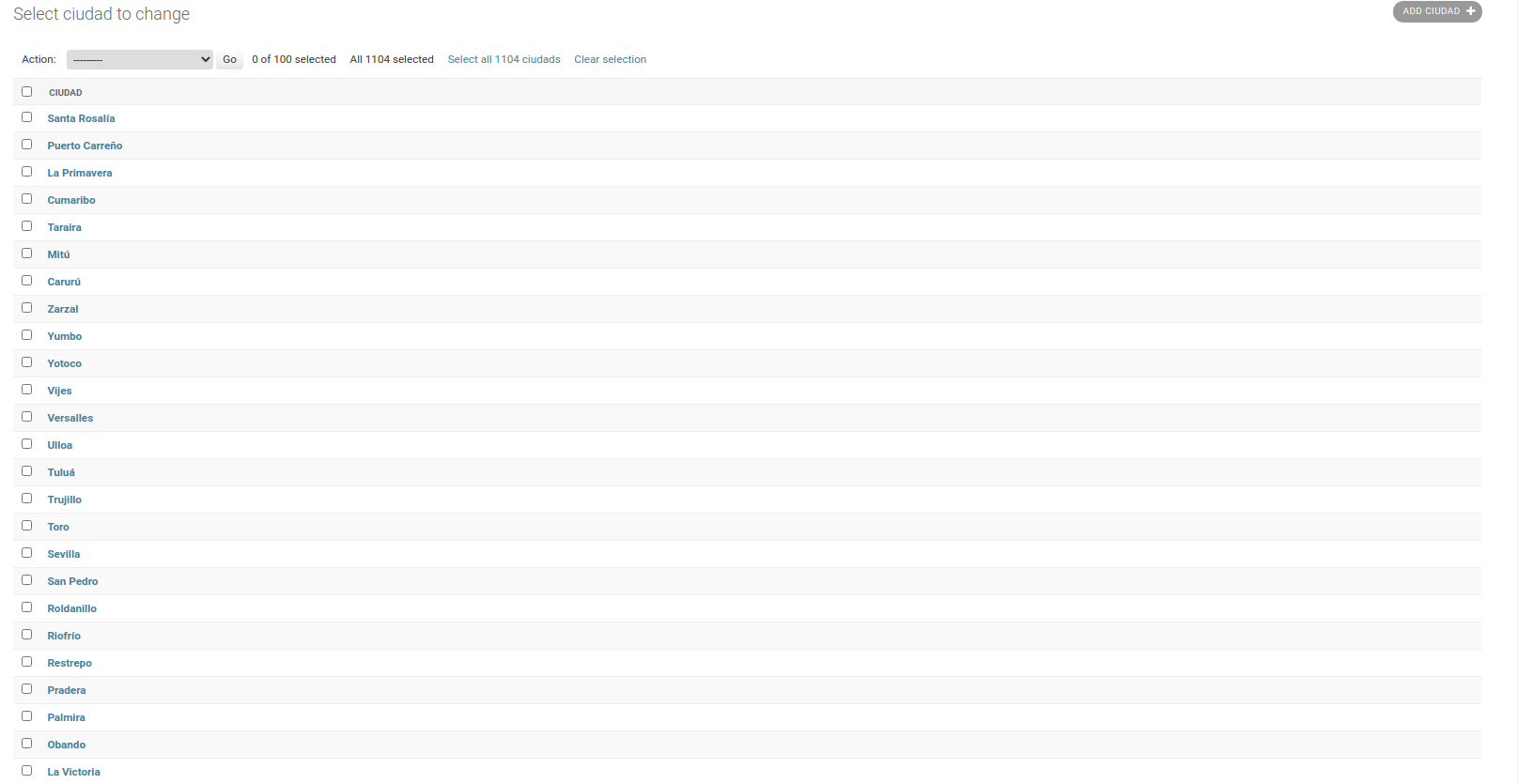
python seed.pycomo resultado final podemos ver todas las ciudades cargadas desde el admin
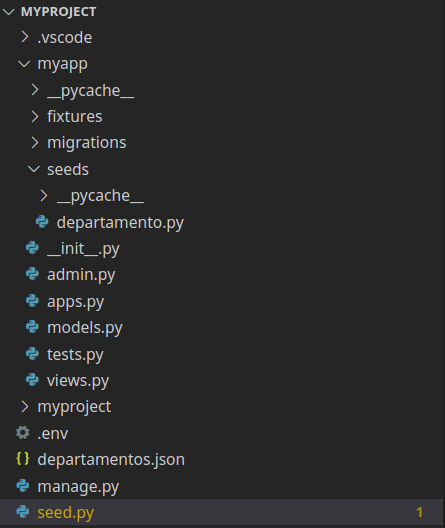
Finalmente agrego una imagen de cómo debería ser la estructura de carpetas del proyecto
la función principal de este ejemplo se encuentra en el archivo departamento.py dentro del folder seeds en myapp este archivo tiene dos métodos el primero es el método should_run que se encargará de validar si debería ejecutarse el código o no, lo interesante aquí es que se puede agregar la lógica que se desee, en mi caso simplemente pregunto que si ya existe información no se ejecute, el método run contiene toda la lógica para registrar departamentos y ciudades leídos del archivo departamentos.json, seguidamente el archivo seed.py carga la ubicacion del archivo settings de django a las variables de entorno para poder ejecutar el orm, además carga variables de entorno que se pueden necesitar para acceder a la base de datos, y en la ejecución del seed pregunta si debería ejecutarlo, si la respuesta es verdadera llama al método run
Este método además se puede usar también para ejecutar otros scripts cuando se necesita trabajar directamente con el orm, de pronto algunos tienen la opinión de que una opción válida es cargar información sin utilizar el orm y utilizando directamente sql lo cual estaría bien , sin embargo las consultas pueden volverse complejas a medida que se cargue información que tenga diferentes relaciones
Conclusión
Como mencione al principio al tener diferentes entornos tener un método para cagar información que le permita a la aplicación estar en un estado de inicio validado siempre es necesario, aquí expuse dos métodos que pueden adoptarse relativamente fácil, quizás el segundo es un método más personalizable pero a la vez requiere más código, este segundo método puede darle un valor agregado cuando se quieran ejecutar scripts que requieran usar el orm de django.