

Hace poco veía un tweet bastante interesante sobre un nuevo feature que se podría agregar a python 3.10, donde se mostraran sugerencias que aparecen al escribir mal los atributos de una librería como se aprecia en la Figura 1
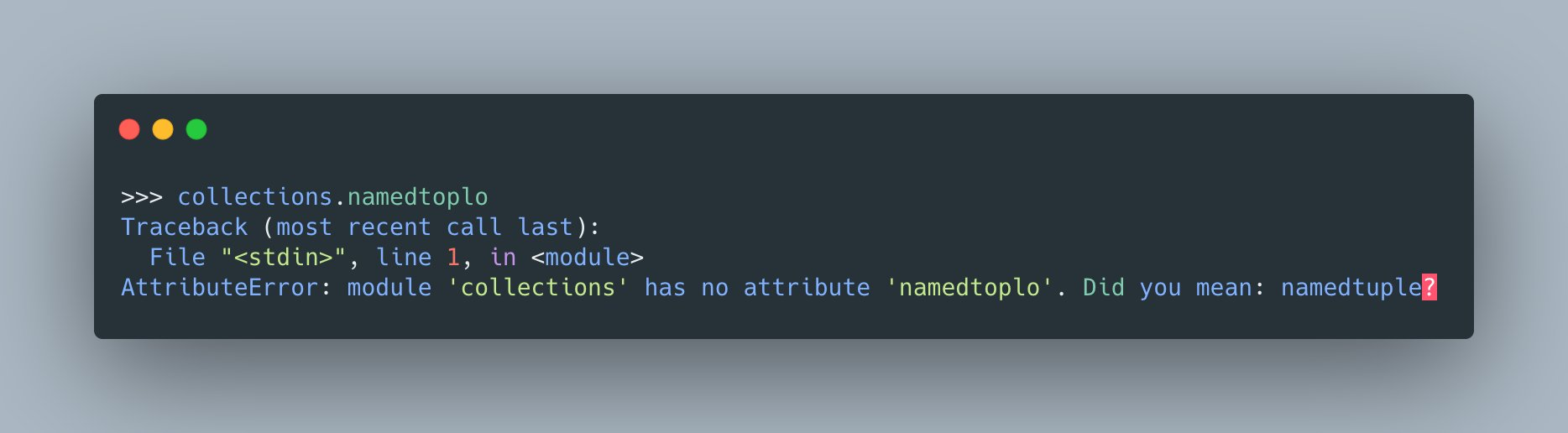
este feature de sugerencia funciona con Levenshtein Distance este es un string metric que permite medir la distancia entre dos cadenas de caracteres, básicamente para saber que tan similares son, esto es muy usado por buscadores y como vimos también en tools de consola para ayudar a corregir errores, la formalización de lo que hace levenshtein distance se aprecia en la Figura 2
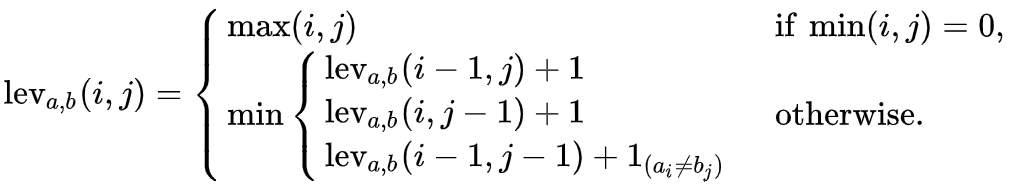
en este post no abordaremos a fondo en como funciona, y seremos mas utilitaristas (entender que sucede por debajo siempre es necesario dejo este post que lo explica muy bien) usando una librería que nos ayudará a resolver este problema de cadenas de string, esto me recuerda a un comic en donde se explicaba cómo volar con python ver Figura 3

Levenshtein a muy alto nivel básicamente funciona comparando dos cadenas de texto A y B con estas dos cadenas se cuentan las veces que debe modificarse A para quedar igual a la cadena B veamos un ejemplo con las cadenas CAT y CAP

en el ejemplo anterior la distancia Levenshtein es de 1 . Es importante aclarar que en el ejemplo anterior se utilizó la cadena A para parecerse a B para simplificar la explicación, pero puede también cambiarse la cadena B para que se parezca a A
Entendiendo un poco como funciona el algoritmo, en el mundo del desarrollo algunas veces necesitamos poder comparar cadenas de texto para saber qué tan similares son, para el ejemplo en código utilizaremos una lista de modelos de carros encontradas en github y le pasaremos nombres incompletos tratando de encontrar el que más se acerque, pasemos al código
Instalaremos la librería fuzzywuzzy utilizando poetry
poetry add fuzzywuzzyadicionalmente para que la libreria funcione de manera más eficiente agregaremos la librería llamada python-Levenshtein
poetry add python-Levenshteinutilizaremos la siguiente data en json
[
{
"Name":"chevrolet chevelle malibu",
"Miles_per_Gallon":18,
"Cylinders":8,
"Displacement":307,
"Horsepower":130,
"Weight_in_lbs":3504,
"Acceleration":12,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"buick skylark 320",
"Miles_per_Gallon":15,
"Cylinders":8,
"Displacement":350,
"Horsepower":165,
"Weight_in_lbs":3693,
"Acceleration":11.5,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"plymouth satellite",
"Miles_per_Gallon":18,
"Cylinders":8,
"Displacement":318,
"Horsepower":150,
"Weight_in_lbs":3436,
"Acceleration":11,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"amc rebel sst",
"Miles_per_Gallon":16,
"Cylinders":8,
"Displacement":304,
"Horsepower":150,
"Weight_in_lbs":3433,
"Acceleration":12,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"ford torino",
"Miles_per_Gallon":17,
"Cylinders":8,
"Displacement":302,
"Horsepower":140,
"Weight_in_lbs":3449,
"Acceleration":10.5,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"ford galaxie 500",
"Miles_per_Gallon":15,
"Cylinders":8,
"Displacement":429,
"Horsepower":198,
"Weight_in_lbs":4341,
"Acceleration":10,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"chevrolet impala",
"Miles_per_Gallon":14,
"Cylinders":8,
"Displacement":454,
"Horsepower":220,
"Weight_in_lbs":4354,
"Acceleration":9,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"plymouth fury iii",
"Miles_per_Gallon":14,
"Cylinders":8,
"Displacement":440,
"Horsepower":215,
"Weight_in_lbs":4312,
"Acceleration":8.5,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"pontiac catalina",
"Miles_per_Gallon":14,
"Cylinders":8,
"Displacement":455,
"Horsepower":225,
"Weight_in_lbs":4425,
"Acceleration":10,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"amc ambassador dpl",
"Miles_per_Gallon":15,
"Cylinders":8,
"Displacement":390,
"Horsepower":190,
"Weight_in_lbs":3850,
"Acceleration":8.5,
"Year":"1970-01-01",
"Origin":"USA"
},
{
"Name":"citroen ds-21 pallas",
"Miles_per_Gallon":null,
"Cylinders":4,
"Displacement":133,
"Horsepower":115,
"Weight_in_lbs":3090,
"Acceleration":17.5,
"Year":"1970-01-01",
"Origin":"Europe"
},
{
"Name":"chevrolet chevelle concours (sw)",
"Miles_per_Gallon":null,
"Cylinders":8,
"Displacement":350,
"Horsepower":165,
"Weight_in_lbs":4142,
"Acceleration":11.5,
"Year":"1970-01-01",
"Origin":"USA"
}
]import json
from fuzzywuzzy import process
def get_car_models_name():
with open("data.json", encoding="utf-8", mode="r") as data:
car_models = json.load(data)
car_name_models = [car_model["Name"] for car_model in car_models]
return car_name_models
def search_model_car(model_name: str):
car_models_name = get_car_models_name()
return process.extractOne(model_name, car_models_name)
print(search_model_car("CoNcurOs"))
Ejecutamos el código
poetry run python main.pyy el resultado es una tupla que contiene la cadena encontrada y un porcentaje de similitud
('chevrolet chevelle concours (sw)', 79)En el ejemplo del código anterior utilizamos la librería fuzzywuzzy esta utiliza el algoritmo de Levenshtein y basado en las distancia obtenidas otorga unos porcentajes y a partir de ello devuelve el que más porcentaje tiene de similitud con la cadena a comparar dado que estamos solicitando a la librería que devuelva uno, sin embargo se podría también solicitar que a cada cadena le ponga un porcentaje como se muestra a continuación
import json
from fuzzywuzzy import process
from fuzzywuzzy import fuzz
def get_car_models_name():
with open("data.json", encoding="utf-8", mode="r") as data:
car_models = json.load(data)
car_name_models = [car_model["Name"] for car_model in car_models]
return car_name_models
def search_model_car(model_name: str):
car_models_name = get_car_models_name()
return process.extract(model_name, car_models_name, limit=3, scorer=fuzz.ratio)
print(search_model_car("CoNcurOs"))ejecutamos el código
poetry run python main.pyy obtenemos el siguiente resultado
[('chevrolet chevelle concours (sw)', 79), ('chevrolet chevelle malibu', 34), ('plymouth satellite', 34)]
obtenemos una lista de tuplas con el nombre de la cadena y porcentaje de similitud, esto porque en el método search_model_car se modifico la siguiente porcion de codigo
return process.extract(model_name, car_models_name, limit=3, scorer=fuzz.ratio)aquí ahora se le dice que devuelva una lista de las 3 primeras que más porcentaje de similitud tengan, adicionalmente como vimos se agregó un parámetro score, esto es porque la librería permite utilizar scores que son funciones que facilitan calcular la similitud de las cadenas pero de diferentes formas como veremos a continuación
- fuzz.ratio: es el método por defecto aquí aplica el algoritmo de levenshtein tal cual se explico al principio del post
- fuzz.partial_ratio: esta función utiliza la similitud de cadenas pero de forma parcial, utilizando el tamaño de la cadena A para buscar coincidencias comparando con subcadenas de B del tamaño de A y obtener un mejor resultado observemolo en código
from fuzzywuzzy import fuzz
def partial():
return fuzz.partial_ratio("Mother","My mother is beautiful")
def default():
return fuzz.ratio("Mother","My mother is beautiful")
print(f"Partial score {partial()}")
print(f"Default score {default()}")Ejecutando el código tenemos las siguientes salidas
Partial score 83
Default score 43como podemos observar en el Partial score al comparar subcadenas la score es muchisimo mas alto que una comparación por defecto, por ende esta función es buena opción si se sabe de antemano que la cadena A podría ser una subcadena de B
- fuzz.token_sort_ratio: esta función especialmente se encarga de ordenar primero los tokens de las cadenas intentando obtener un mejor resultado al aplicar el algoritmo, veamos un ejemplo
from fuzzywuzzy import fuzz
def partial(data_to_search:str,data:str):
return fuzz.partial_ratio(data_to_search,data)
def default(data_to_search:str,data:str):
return fuzz.ratio(data_to_search,data)
def order(data_to_search:str,data:str):
return fuzz.token_sort_ratio(data_to_search,data)
print(f"Partial score {partial('Lakers vs Golden state warriors', 'Golden state warriors vs Lakers')}")
print(f"Default score {default('Lakers vs Golden state warriors', 'Golden state warriors vs Lakers')}")
print(f"Token sort score {order('Lakers vs Golden state warriors', 'Golden state warriors vs Lakers')}")Al ejecutar el código obtenemos el siguiente resultado
Partial score 68
Default score 68
Token sort score 100como podemos observar los primeros métodos no obtienen un buen resultado en comparación con el 100% del Token sort, ya que ordenó los tokens de las cadenas para obtener este resultado
- fuzz.token_set_ratio esta función utiliza las subcadenas de A para hacer intersección contra las subcadenas de B y retornando la que obtenga el mayor porcentaje de similitud, veamos un ejemplo
from fuzzywuzzy import fuzz
def partial(data_to_search:str,data:str):
return fuzz.partial_ratio(data_to_search,data)
def default(data_to_search:str,data:str):
return fuzz.ratio(data_to_search,data)
def order(data_to_search:str,data:str):
return fuzz.token_sort_ratio(data_to_search,data)
def set_ratio(data_to_search:str,data:str):
return fuzz.token_set_ratio(data_to_search,data)
print(f"Partial score {partial('mariners vs angels', 'los angeles angels of anaheim at seattle mariners')}")
print(f"Default score {default('mariners vs angels', 'los angeles angels of anaheim at seattle mariners')}")
print(f"Token sort score {order('mariners vs angels', 'los angeles angels of anaheim at seattle mariners')}")
print(f"Token set ratio score {set_ratio('mariners vs angels', 'los angeles angels of anaheim at seattle mariners')}")y de salida en consola obtenemos
Partial score 61
Default score 36
Token sort score 51
Token set ratio score 91vemos como el Token set ratio obtiene un mayor porcentaje debido a su método de la intersección de cadenas
Conclusión
Esta librería es muy útil a la hora de trabajar con comparaciones con cadenas, a veces incluso los query de los motores de bases de datos no son suficientes debido a que las cadenas varían demasiado con lo que se tiene guardado, por tanto esta es una buena opción para enfrentarse a este tipo de situaciones