

La computación en la nube ya lleva un buen tiempo posicionándose, las empresas entendieron la necesidad de usar servicios en nube para poder seguir siendo competitivos, sin embargo usar nube trae consigo algunas implicaciones como: legales, económicas, técnicas (no necesariamente usar nube es más económico) debido a ello procesos dentro de devops (Ver Figura 1) ayudan a los equipos de desarrollo y operaciones a ser más eficientes, logrando de esta manera optimizar sus despliegues, esta mezcla de devs y ops no solo ocurre en la teoría, también ocurre en la práctica y una estrategia eficiente para gestionar los recursos en nube es utilizar IAC infraestructure as a code

Infrastructure as a code
La definición e IAC es un poco sencilla, consiste en poder automatizar, aprovisionar, gestionar y eliminar recursos en nube pero utilizando un lenguaje que facilite la estructura y replicación de estos procesos. Los beneficios son varios entre ellos reducción de tiempos, ya que trabajas de manera más eficiente con los equipos, no hay "centralización del conocimiento" es decir no es una persona la que conoce cómo hacer "X" o "Y" si no que existe un conjunto de templates o de código que lo realiza, aumento de la productividad: es importante por que muchos procesos se vuelven tediosos y aburrido y esto puede conllevar a pérdida de talento, facilidad de automatización: los desarrolladores siempre están pensando en automatizar cosas aburridas, al tener el ambiente ideal para hacerlo seguro se le ocurrirán cosas ideas bastante interesantes
Tienes miedo a cambiar algo en tu infraestructura?
Es una de las preguntas que se usa mucho cuando habla de implementar TDD, en infraestructura podríamos cambiar un poco la pregunta, podrías borrar tu infraestructura y volverla a recrear fácilmente?, actualmente las aplicaciones nacen nativamente cloud, las empresas piensan primero en nube, tener la capacidad de subir una infraestructura para probar y rápidamente borrarla, pasarla a stage, moverla a producción, eliminarla (Los componentes de infraestructura que no tienen estado deben ser fácil de cambiar, los demás deben ser inmutables) esto es algo necesario, hacer estos procesos manualmente demanda una gran cantidad de trabajo, además no es versionable (no puedo volver a difernetes puntos) con todo esto es entendible que tengas miedo a cambiar algo de tu infraestructura por que es como jugar jenga
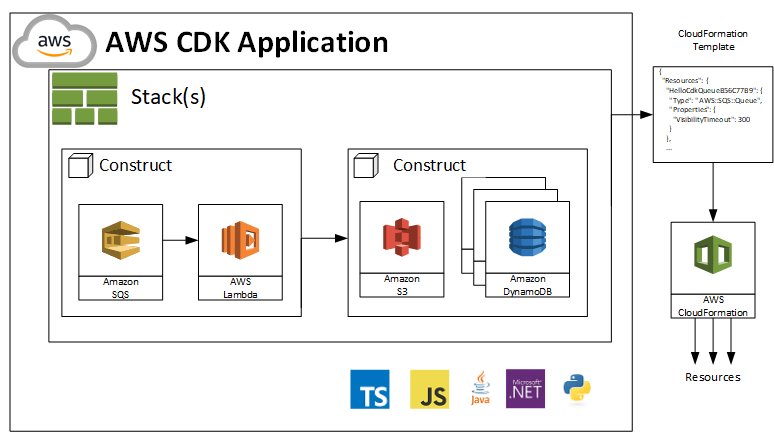
CDK
El cloud development kit es una librería realizada por amazon para gestionar infraestructura en su nube utilizando diferentes lenguajes de programación, cdk tiene dos principales componentes, el cli que es la herramienta que nos ayuda a gestionar todo el proceso de automatización y el código donde indicaremos la infraestructuras que queremos construir. La función principal de CDK es gestionar la infraestructura utilizando lenguajes de programación muy populares como: TS, JS, Java, python y estos son transformados a templates de cloudformation, el cual es el servicio específico de aws para desplegar infraestructuras con templates, hay gran cantidad de beneficios de usar CDK sobre los template de cloud formation, uno de los mas importantes es la capacidad de tener toda la potencia que ofrece un lenguaje, functions, herencia, abstracciones e infinidad de ventajas adicionales
Desplegando una lambda
Mostraré un ejemplo sencillo, usando dynamodb y una lambda con api gateway, los primero para empezar es instalar cdk, es importante tener aws configurado con credenciales
npm install -g aws-cdkahora con el cli creare una estructura de proyecto con el siguiente comando
cdk init myproject --language pythoncon ello tendremos la estructura de proyecto para trabajar, ahora el cdk maneja algo llamado constructs que son básicamente recursos de aws, para poder usarlos debo instalarlos, yo usare lambda, dynamodb y api gateway, así que instalare los siguientes
pip install aws-cdk.aws-apigateway aws-cdk.aws-dynamodb aws-cdk.aws-lambdadentro de la carpeta myproject creada creare un módulo llamado mystack con el siguiente código
from aws_cdk import (
core,
aws_lambda as _lambda,
aws_dynamodb as _dynamodb,
aws_apigateway as _apigateway,
)
class MyProjectStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
my_user_table = _dynamodb.Table(
self,
"MyUserTable",
partition_key=_dynamodb.Attribute(
name="user_id", type=_dynamodb.AttributeType.STRING
),
)
user_lambda = _lambda.Function(
self,
"UserLambda",
runtime=_lambda.Runtime.PYTHON_3_7,
code=_lambda.Code.from_asset("myproject/lambda"),
handler="user.handler",
)
user_lambda.add_environment("TABLE_NAME", my_user_table.table_name)
user_api = _apigateway.LambdaRestApi(
self, "UserApi", handler=user_lambda, proxy=False
)
user_items = user_api.root.add_resource("user")
user_items.add_method("POST")
my_user_table.grant_read_write_data(user_lambda)
adicional a ello crearé una carpeta lambda y creare un módulo llamado user con el siguiente código
import json
import boto3
import os
from logging import basicConfig, getLogger, INFO
logger = getLogger(__name__)
basicConfig(level=INFO)
dynamodb = boto3.resource("dynamodb")
TABLE_NAME = os.environ["TABLE_NAME"]
def handler(event, context):
user_info = json.loads(event["body"])
user_table = dynamodb.Table(TABLE_NAME)
logger.info(user_info)
response = user_table.put_item(Item=user_info)
logger.info("User created")
logger.info(response)
return {"statusCode": 200}para ejecutar el despliegue, el código debe subirse a aws, este tiene que guardarlo en un bucket, para ello se utiliza el comando bootstrap
cdk bootstrap --profile=myprofileluego de ello se ejecuta el comando deploy
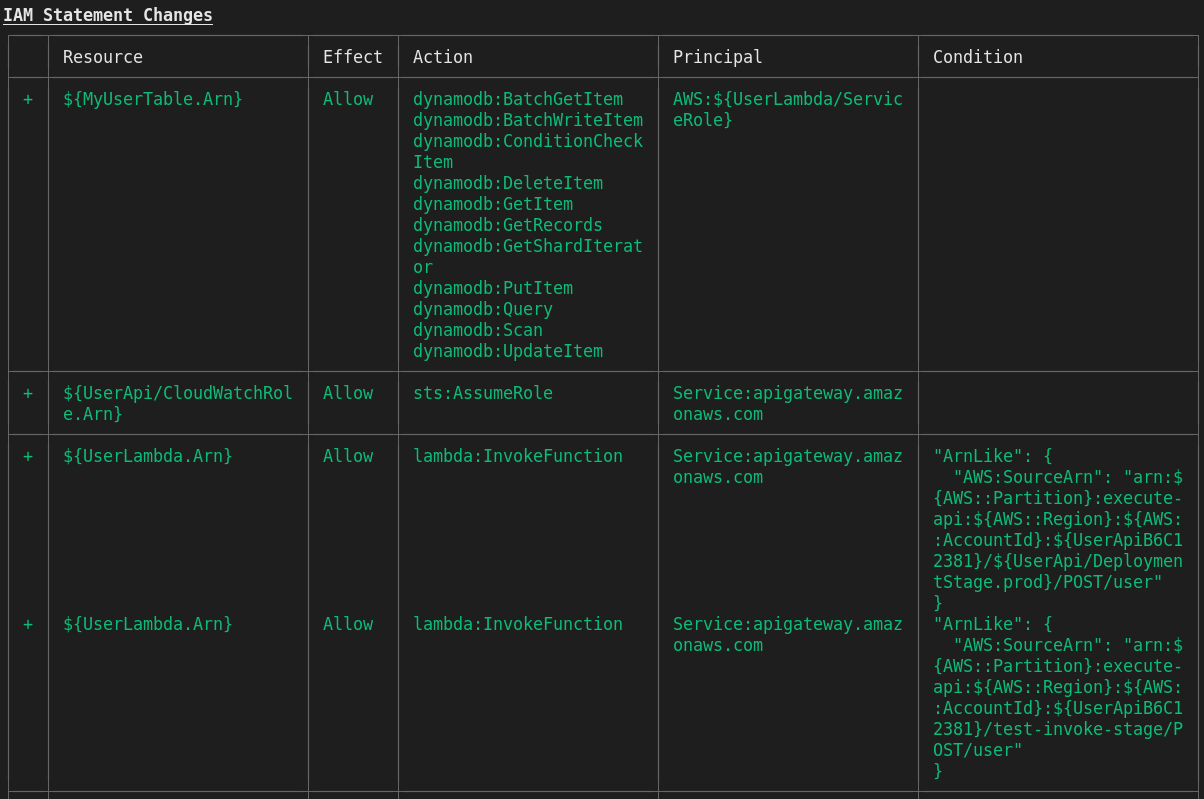
cdk deploy --profile=myprofileuna de las cosas más geniales de cdk que me ha gustado, es justamente cuando despliegas te muestra qué permisos debes configurar, ya que generalmente en entornos de producción no tienes cuentas con todos los permisos a todos los recursos y es algo muy pero muy tedioso estar ejecutando y generando errores, esto se aprecia en la siguiente Figura
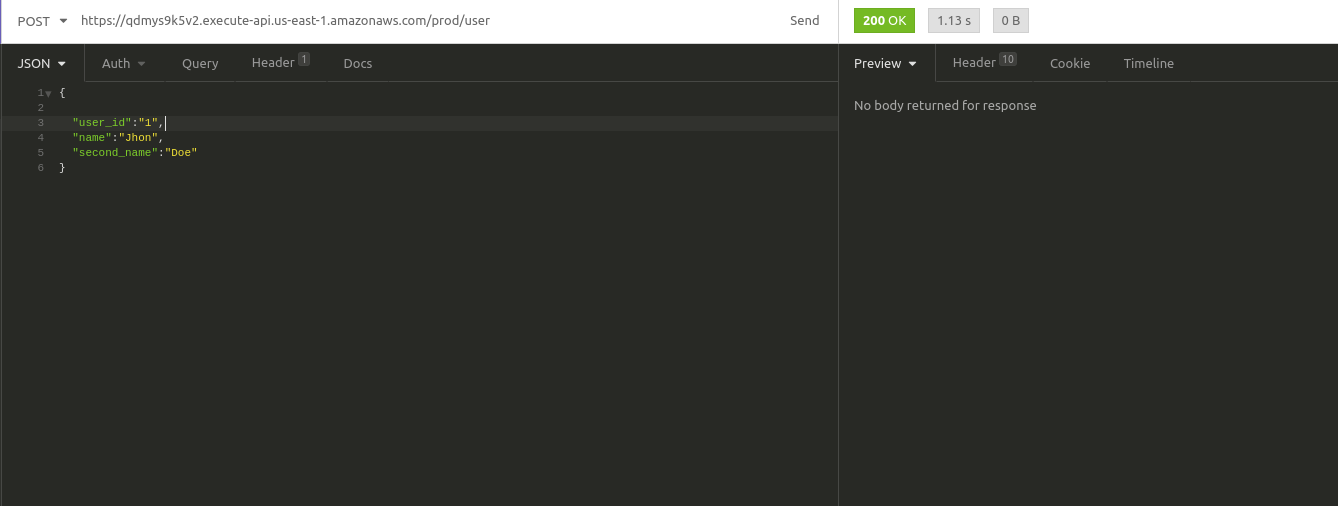
al desplegar, me retorna un endpoint para probar, y pruebo ejecutando insomnia
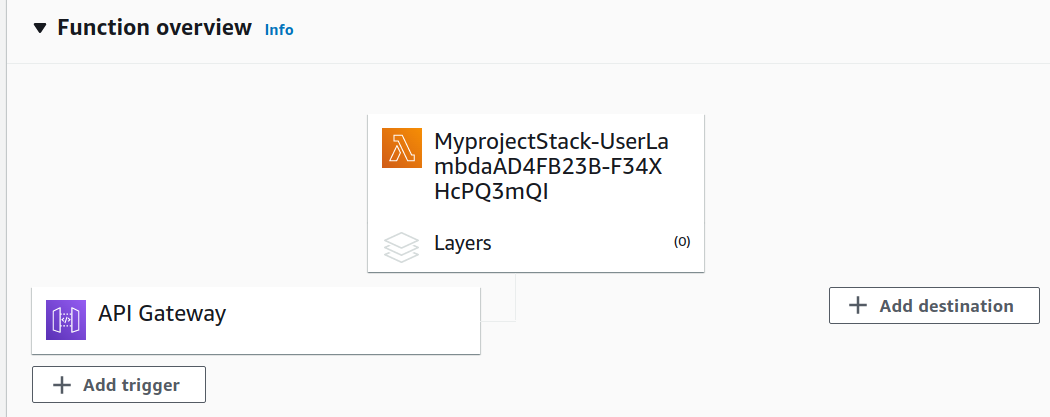
también desde la consola de AWS se puede apreciar el template de cloudformation ejecutado y los recursos individuales creados

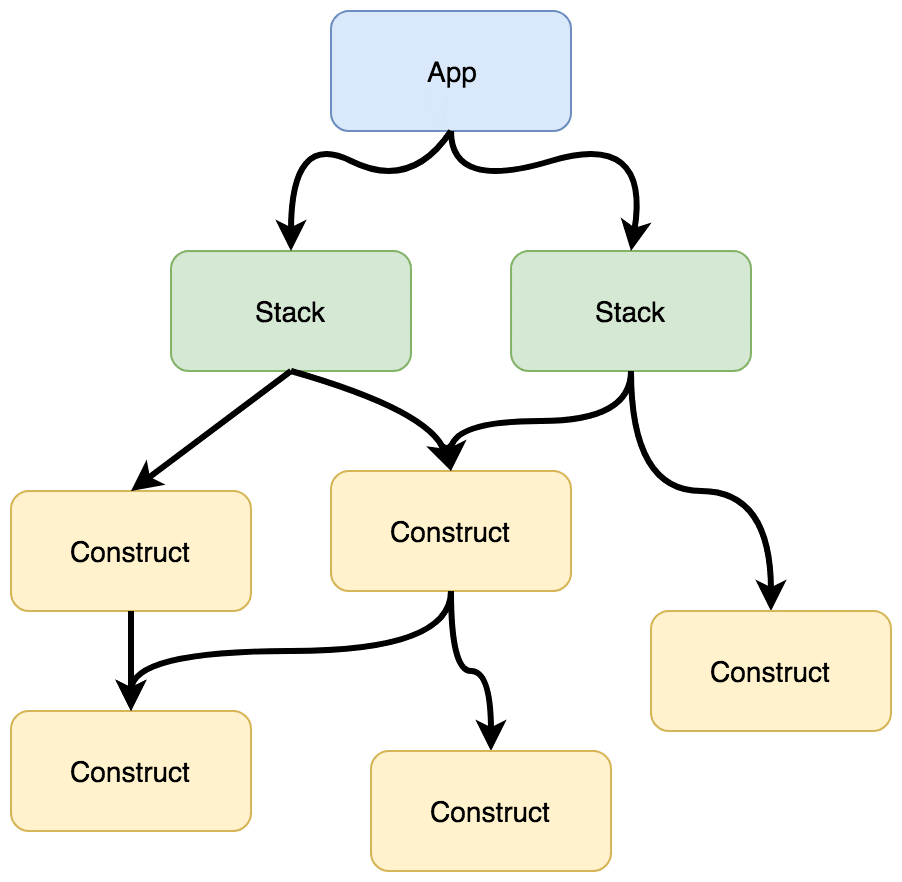
para entender un poco que hace el código, lo primero es entender cómo se trabaja el cdk ver Figura 7, esta se constituye de una app que es como la raíz de un árbol, a partir de aquí se pueden tener stacks diferentes es decir yo puedo tener un stack que contenga una lambda un dynamodb, otro stack que contenga dos lambdas, un gateway , un vpc y un rds. Los stacks se componen de constructs es decir recursos que aws tiene disponible aquí se pueden ver mejor y a partir de estos stacks se construyen los despliegues
class MyProjectStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
my_user_table = _dynamodb.Table(
self,
"MyUserTable",
partition_key=_dynamodb.Attribute(
name="user_id", type=_dynamodb.AttributeType.STRING
),
)
user_lambda = _lambda.Function(
self,
"UserLambda",
runtime=_lambda.Runtime.PYTHON_3_7,
code=_lambda.Code.from_asset("myproject/lambda"),
handler="user.handler",
)
user_lambda.add_environment("TABLE_NAME", my_user_table.table_name)
user_api = _apigateway.LambdaRestApi(
self, "UserApi", handler=user_lambda, proxy=False
)
user_items = user_api.root.add_resource("user")
user_items.add_method("POST")
my_user_table.grant_read_write_data(user_lambda)en este segmento de código estoy creando un stack, este es una clase que hereda de core.Stack aquí creo dos recursos, un lambda y un dynamodb, para poderlos crear debí instalar los construct que en pasos anteriores lo hize, estos constructs tienen parámetros, los mismos que veríamos en una consola gráfica, por ejemplo en el lambda en la consola de aws se selecciona el runtime, en este caso yo selecciono python 3.7, le agrego nombre al lambda y le digo en donde se ubica el código, este código de lambda usando el comando bootstrap se sube a un bucket S3 y de aquí pasa a referenciarse como function lambda, otro tema interesante en el código que se puede notar, es que los recursos se relacionan entre sí, lo cual siempre es necesario, por ejemplo un lambda necesita tener permisos para escribir a un dynamodb, un api gateway debe definir sus métodos disponibles, sus endpoints y diferentes configuraciones que se tienen, se pueden referenciar variables de entorno usando los recursos ya creados como se puede ver, se crea una variable de entorno TABLE_NAME que después se usa en el código de la lambda.
Al final del dia se esta llevando lo que se hace de forma manual en la infraestructura, que sería construir la tabla de dynamodb, subir el código de lambda, crear sus variables, crear el api gateway configurarlo, todo este proceso de configuración ahora se define en código y se tiene un cli que permite llevar una gestión del cambio, como ven los recursos que no requieren estados como la lambda, cambian constantemente, pero si yo realizo un cambio y hago un deploy, la tabla de dynamodb no se va a borrar, solo se actualiza si tiene cambio de permisos o cualquier otro atributo, esto es una de las grandes ventajas de poder unir la parte operativa con la de código.
Conclusiones
CDK disminuye trabajo que se debe hacer en temas de despliegues, ahorra bastante tiempo para la administración de recursos permite probar prototipos a los equipos de desarrollo rápidamente, pero la complejidad de la infraestructura se mantiene, esto quiere decir que para gestionar los recursos desde cdk debes conocer cómo funcionan, sus configuraciones etc, si no me atrevería a decir que CDK traerá más problemas que soluciones