

Actualmente la información juega un papel importante en las empresas para su toma de decisiones , decenas de sistemas de información, archivos y documentos generando materia prima para sus diferentes tableros de inteligencia de negocio y sus diferentes desarrollos de inteligencia artificial, todo se basa en procesos ETL donde procesar la información inicial para limpiar o convertirla es crucial para lograr los diferentes objetivos propuestos, en las fuentes de información podemos encontrar diferentes formatos csv, xlsx, json, txt y un formato muy conocido que es el formato PDF, en donde puede contener tablas de información necesarias para fuentes de entrada de los diferentes procesos de ETL
Un poco sobre PDF
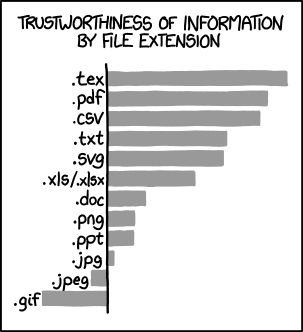
Portable Document Format nace a principios de los años 90 antes del WWW y HTML, la idea en principio era permitir generar documentos que se vieran e imprimieran de la misma forma en cualquier máquina, de ahí el "portable", este se creó como un subset de postscript que era un lenguaje desarrollado por adobe, PDF tiene alrededor de 13 versiones y en el año 2008 fue estandarizado por la ISO, a raíz de todos los beneficios de contener propiamente el contenido y funcionar en cualquier máquina es uno de los formatos más populares sobre todo en facturas de pago áreas de negocio y para generación de informes, adicional a todo ello es uno de los más confiable según nuestra gran fuente xkcd Ver Figura 1 por todo esto pdf se convierte muchas veces en insumo importante para muchos procesos de análisis de información y en este artículo me enfocaré explicar algunos ejemplos de cómo obtener información de pdfs empezando por obtener tablas
Camelot
Es una herramienta enfocada a la extracción de tablas a partir de archivos pdfs (fun fact su nombre viene del camelot project quien dio inicio a lo que sería PDF) una de las cosas que mas me gusto es que utiliza pandas y sus métodos utilizan la misma nomenclatura por ello si vienes de pandas vas a poder familiarizarte muy rápido con ella, por otro lado realizar esta extracción no es un trabajo sencillo de hecho hay una comparación realizada con otras librerías donde camelot logra obtener mejores resultados en estas comparaciones, esto es bastante interesante debido a que la comparación se realizó con tablas de pdfs que tenían una gran complejidad, lo primero para poder usar la librería debemos instalar unas dependencias externas vamos a ello
apt install ghostscript python3-tkluego de ello utilizando poetry instalamos camelot y sus dependencias
poetry add camelot-py[all]con esto ya podemos empezar a trabajar, para ello empezaremos con un ejemplo sencillo utilizando este pdf como fuente primaria
import camelot
def get_first_table(pdf_file: str) -> camelot.core.Table:
tables = camelot.read_pdf(pdf_file)
return tables[0]
def convert_table_to_excel(table: camelot.core.Table, excel_file: str) -> None:
table.to_excel(excel_file)
def main():
pdf_file = "foo.pdf"
excel_file = "foo.xlsx"
table = get_first_table(pdf_file)
convert_table_to_excel(table, excel_file)
if __name__ == "__main__":
main()
ejecuto el codigo
python main.pyy obtengo el siguiente resultado
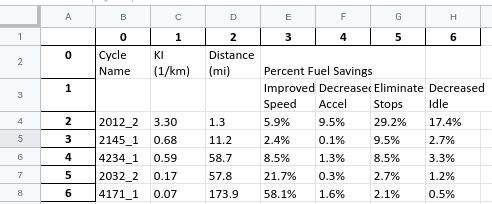
El formato de filas combinadas no se mantiene sin embargo es algo que se puede manejar, en cuanto al código se importa la libreria camelot y se utiliza la función read_pdf() el cual recibe el archivo pdf que leerá, por defecto camelot solo lee la primera pagina, si en ella encuentra varias tablas devuelve una lista por ello en este caso se retorna la posición [0] ya que en una misma pagina puede detectar varias tablas y apartir de aquí utilizando wraps basados en pandas convierte el archivo a excel utilizando la función to_excel(), se pueden hacer algunos ejemplos mas complicados, si se quieren leer mas paginas o el pdf trae password, se puede abrir utilizando el siguiente código
import camelot
def get_first_table_with_password(pdf_file: str, password: str) -> camelot.core.Table:
tables = camelot.read_pdf(pdf_file, password=password, pages="1,2,3,4")
return tables[0]
def convert_table_to_excel(table: camelot.core.Table, excel_file: str) -> None:
table.to_excel(excel_file)
def convert_table_to_csv(table: camelot.core.Table, csv_file: str) -> None:
table.to_csv(csv_file)
def convert_table_to_json(table: camelot.core.Table, json_file: str) -> None:
table.to_json(json_file)
def main():
pdf_file = "foo_protected.pdf"
excel_file = "foo.xlsx"
password = "123456"
table = get_first_table_with_password(pdf_file, password)
convert_table_to_excel(table, excel_file)
convert_table_to_csv(table, "foo.csv")
convert_table_to_json(table, "foo.json")
if __name__ == "__main__":
main()Ejecuto el código
python main.pyy obtengo el siguiente resultado
[
{
"0": "Cycle \nName",
"1": "KI \n(1/km)",
"2": "Distance \n(mi)",
"3": "Percent Fuel Savings",
"4": "",
"5": "",
"6": ""
},
{
"0": "",
"1": "",
"2": "",
"3": "Improved \nSpeed",
"4": "Decreased \nAccel",
"5": "Eliminate \nStops",
"6": "Decreased \nIdle"
},
{
"0": "2012_2",
"1": "3.30",
"2": "1.3",
"3": "5.9%",
"4": "9.5%",
"5": "29.2%",
"6": "17.4%"
},
{
"0": "2145_1",
"1": "0.68",
"2": "11.2",
"3": "2.4%",
"4": "0.1%",
"5": "9.5%",
"6": "2.7%"
},
{
"0": "4234_1",
"1": "0.59",
"2": "58.7",
"3": "8.5%",
"4": "1.3%",
"5": "8.5%",
"6": "3.3%"
},
{
"0": "2032_2",
"1": "0.17",
"2": "57.8",
"3": "21.7%",
"4": "0.3%",
"5": "2.7%",
"6": "1.2%"
},
{
"0": "4171_1",
"1": "0.07",
"2": "173.9",
"3": "58.1%",
"4": "1.6%",
"5": "2.1%",
"6": "0.5%"
}
]"Cycle
Name","KI
(1/km)","Distance
(mi)","Percent Fuel Savings","","",""
"","","","Improved
Speed","Decreased
Accel","Eliminate
Stops","Decreased
Idle"
"2012_2","3.30","1.3","5.9%","9.5%","29.2%","17.4%"
"2145_1","0.68","11.2","2.4%","0.1%","9.5%","2.7%"
"4234_1","0.59","58.7","8.5%","1.3%","8.5%","3.3%"
"2032_2","0.17","57.8","21.7%","0.3%","2.7%","1.2%"
"4171_1","0.07","173.9","58.1%","1.6%","2.1%","0.5%"
En el código anterior modifique la función get_first_table_with_password() la cual ahora permite enviar cargar archivos que tienen restricción de contraseña, adicionalmente este archivo tiene dos páginas para indicarle a camelot en que páginas debe buscar las tablas, agregue varios métodos para transformar el resultado de las tablas no solo a excel si no a csv y json y finalmente es importante saber que se puede adicionalmente cargar la información como dataframes por lo que tendremos todos los beneficios que se tienen de operaciones vectoriales que se requieren y que se pueden hacer con pandas, aquí abajo un ejemplo
import camelot
def get_data_frame(pdf_file: str) -> camelot.core.Table:
tables = camelot.read_pdf(pdf_file)
return tables[0].df
def main():
pdf_file = "foo.pdf"
table_data = get_data_frame(pdf_file)
table_data["Total"] = table_data.iloc[1:, 1].sum()
print(table_data["Total"])
if __name__ == "__main__":
main()
ejecuto el codigo y obtengo el siguiente resultado
0 3.300.680.590.170.07
1 3.300.680.590.170.07
2 3.300.680.590.170.07
3 3.300.680.590.170.07
4 3.300.680.590.170.07
5 3.300.680.590.170.07
6 3.300.680.590.170.07
en el código anterior cuando cargo la tabla llamó al atributo .df y esto me devuelve un dataframe de pandas el cual ya se puede utilizar todas sus funciones como iloc, loc y muchos mas yo escribí un post sobre esta gran herramienta donde profundizo un poco más
Excalibur
Esta herramienta podría decirse que es un complemento de camelot pero es 'No-Code' es decir es totalmente gráfica por debajo utiliza camelot y otras herramientas que potencian el proceso de conversión de manera sencilla, para ejecutarlo se instala
poetry add excalibur-pyluego se inicializa la db y se ejecuta el servidor
excalibur initdbexcalibur webserver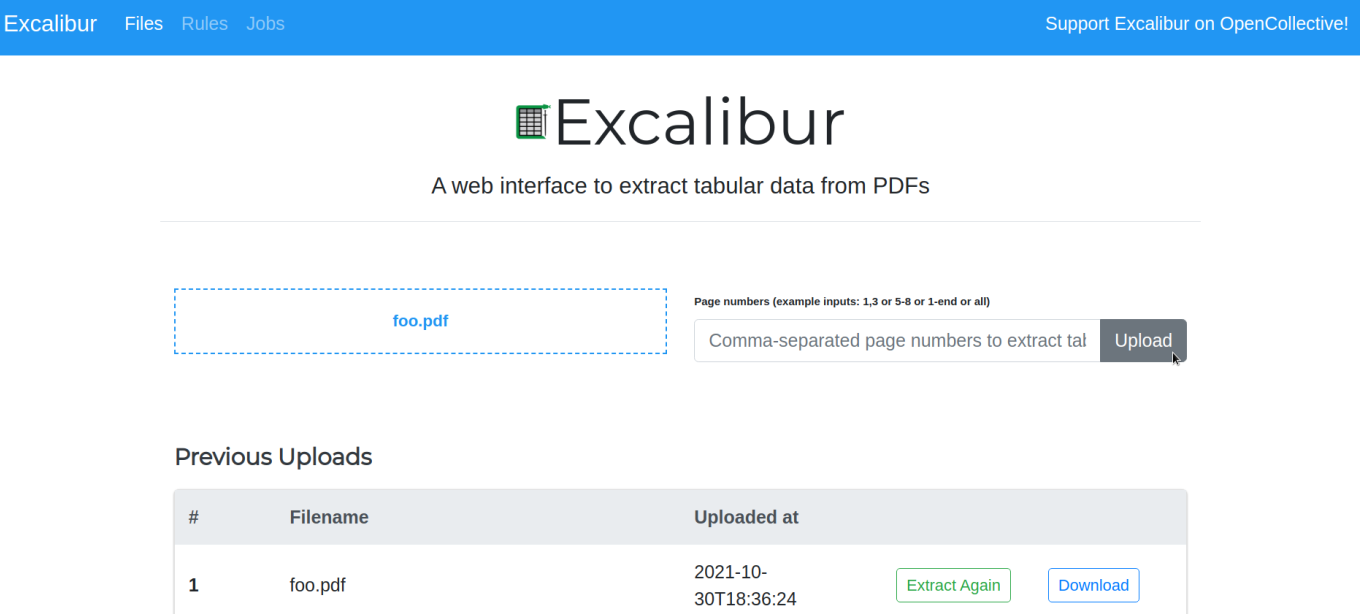
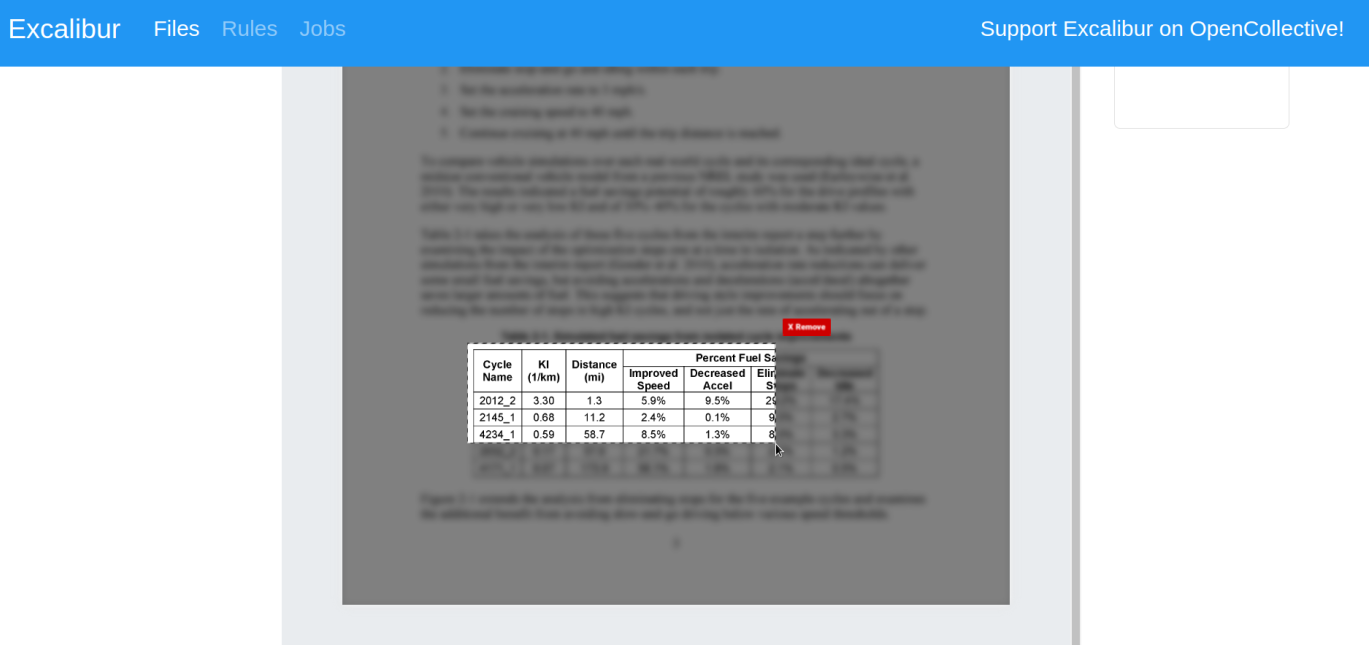
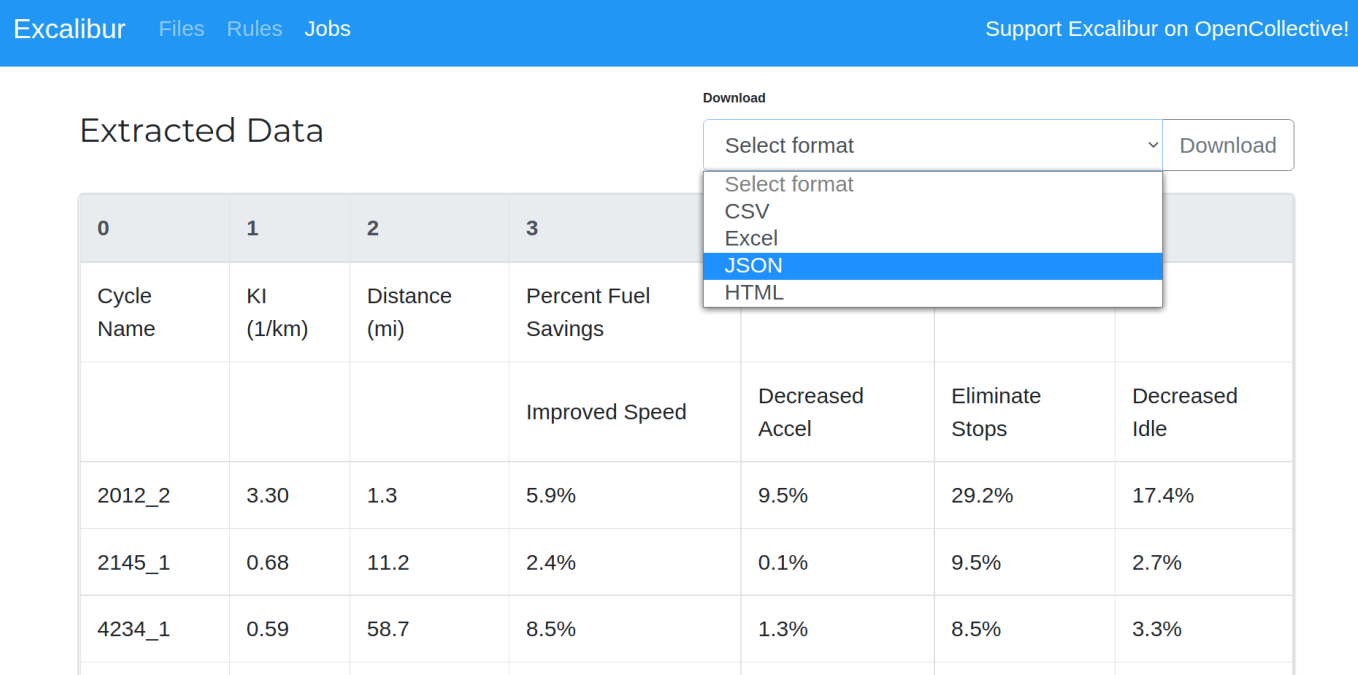
Utilizando excalibur los pasos son muy sencillos
- Se selecciona el archivo pdf que se desea extraer las tablas
- Se autodetecta las tablas o manualmente utilizando un selector gráfico se marcan
- Se exporta la información en el formato que se desee
Conclusiones
Extraer información de los archivos pdf siempre sera un trabajo bastante complicado, existen muchas librerías e incluso plataformas pagan que lo hacen pero sin duda camelot y excalibur son dos herramientas muy buenas, fáciles de manejar y que se integran con todo el ecosistema de data science y sus librerías mas populares