

Hace poco hable un poco sobre pandas una librería para trabajar con información heterogénea y tabulada, otorgando una interface con una gran cantidad de funciones disponibles para manipular información, en mi artículo anterior hice una comparación entre pandas y openpyxl consciente de que seguramente no gustaria mucho debido que pandas es un universo más grande que openpyxl, por eso quise seguir esa línea y dedicar un artículo en solitario para trabajar con el motor de pandas y sus funciones, por cierto su nombre según wikipedia deriva del concepto de panel data y su logo seguramente transmite esa idea Ver Figura 1 (si yo también quería el logo con un panda)

DataFrame
Los dataframes en pandas son estructuras de dos dimensiones, podría decirse que son arrays, ciertamente tienen algún comportamiento similar a los dicts pero con su respectiva especialización enfocada a datos cargados desde archivos excel, podríamos pensar en un dataframe como una matriz, como se aprecia a continuación para el ejemplo cargare un csv de datos abiertos
from os import read
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location)
print(result.info())
read_csv()
ejecuto y obtengo el siguiente resultado
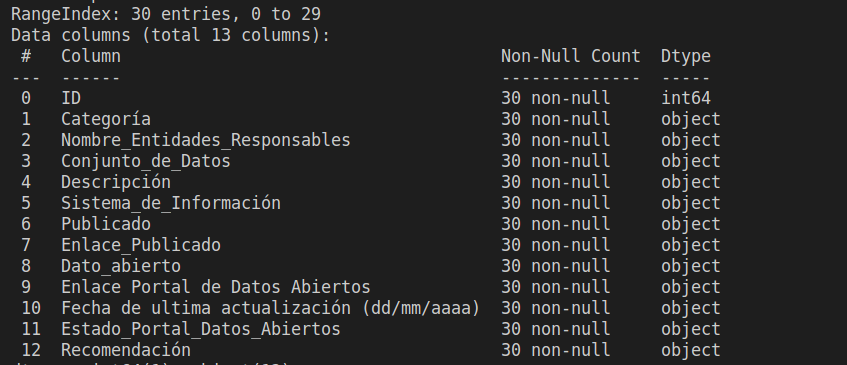
el codigo me devuelve lo que sería un dataframe 30 filas 13 columnas e información muy importante sobre este data frame, pandas maneja algunos tipos de datos propios de la librerías, generalmente cuando se cargan datos la mayoría vienen tipo object que este tipo de dato es una mezcla entre caracteres y números que aun no se han definido, otro dato a destacar es que me indica si vienen datos nulos, esto por que puede ser que los nulos no me sirvan y requiera eliminar esa columna o filas nulas, otra forma para saber si se tiene datos por columnas nulos es con el siguiente código
from os import read
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location)
print(result.isnull().any())
read_csv()ejecuto y puedo apreciar el resultado
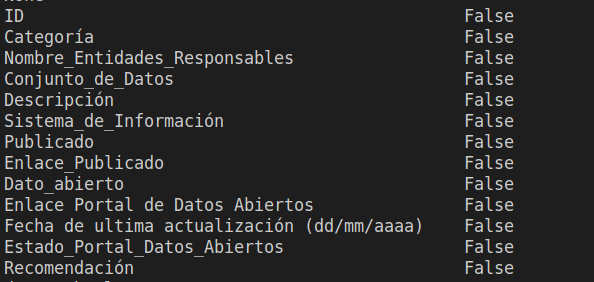
como se aprecia devuelve las columnas y un booleano indicando si existen valores nulos en esas columnas, al no existir ya se sabe que la transformación de borrado no se debe hacer, para mostrar la información podríamos necesitar de algunos parámetros adicionales debido a que pueden existir muchas columnas y no logran verse, veamos el siguiente ejemplo
from os import read
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location)
print(result[:5])
read_csv()ejecuto y tengo el siguiente resultado

en este caso vemos que no nos muestra si no una columna esto debido a que son 12 y todas tienen gran cantidad de texto, para eso necesitaremos de una herramienta de filtrado
Slicing ,Iloc, Loc
Si ya habías trabajado en python este concepto no te será nuevo, es una forma de indexar o mejor aún filtrar contenido de listas utilizando mezclas de parámetros de posiciones, por ejemplo yo podría hacer un filtrado para traer los datos desde el index 10 en adelante el código se vería así
from os import read
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location)
print(result[10:])
read_csv()
ejecuto y obtengo el siguiente resultado
el filtrado lo hace pandas automáticamente por el index, por ende consulta cuales son los mayores 10 y los devuelve, esto esta cool pero limitado necesitamos filtros más elaborados donde usemos el concepto matricial para ello acudiré a dos atributos loc e iloc
Iloc
Más que funciones son atributos ya que son expuestos por medio de una interfaz por eso su particular uso [], el atributo iloc básicamente y para no complicar el asunto permite indexar utilizando posiciones y solamente datos numéricos como se aprecia a continuación
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def filter_data_iloc():
data = read_csv()
print("first 3 rows and first 3 columns")
print()
print(data.iloc[:3, :3])
print()
print("after row 7 and columns with position 0,1,2,4,5")
print()
print(data.iloc[7:, [0,1,2,4,5]])
filter_data_iloc()
ejecuto y el resultado se aprecia a continuación
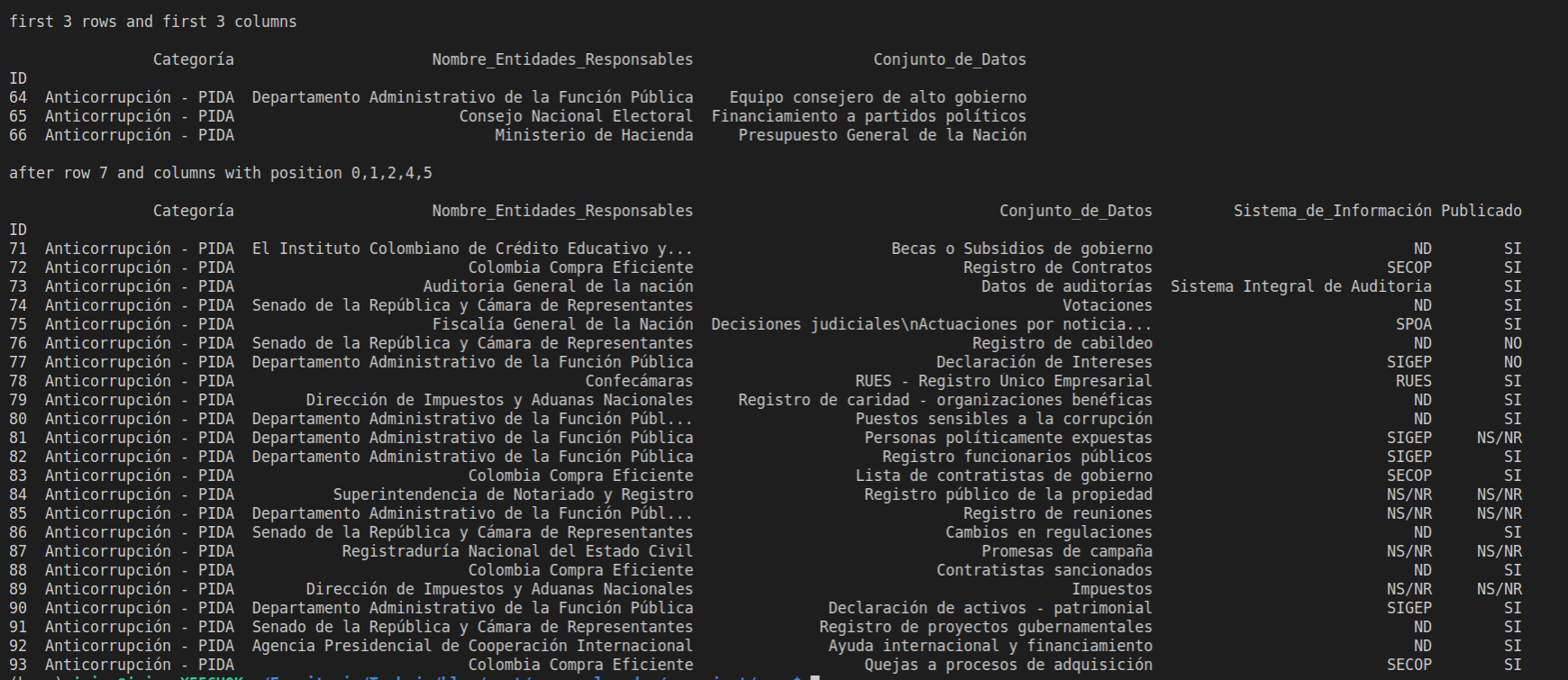
como ven el primero .iloc imprime las primeras tres filas y las primeras 3 columnas, las columnas cargadas se cuentan de izquierda a derecha dando una posición a cada una, la primera columna tendrá la posición 0, la segunda la 1 y así sucesivamente, el segundo iloc permite traer la filas después de la posición 7 y trae unas columnas en específicas pasando una lista de posiciones en este caso 0,1,2,4,5
Loc
Igualmente este es un atributo, estos atributos se crearon para permitir hacer el slicing menos complejo por eso antes de usar iloc o loc recomiendo leer sobre slicing la diferencia aquí es que loc permite hacer slicing utilizando labels veamos el mismo ejemplo de arriba pero con .loc
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def filter_data_loc():
print()
data = read_csv()
print("first 3 rows and first 3 columns")
print()
print(data.loc[64:66, :"Conjunto_de_Datos"])
print()
print("after row with index 70 and columns with position name Categoría,Nombre_Entidades_Responsables,Sistema_de_Información,Publicado")
print()
print(data.loc[70:, ["Categoría","Nombre_Entidades_Responsables","Sistema_de_Información","Publicado"]])
filter_data_loc()
ejecuto y obtengo el siguiente resultado
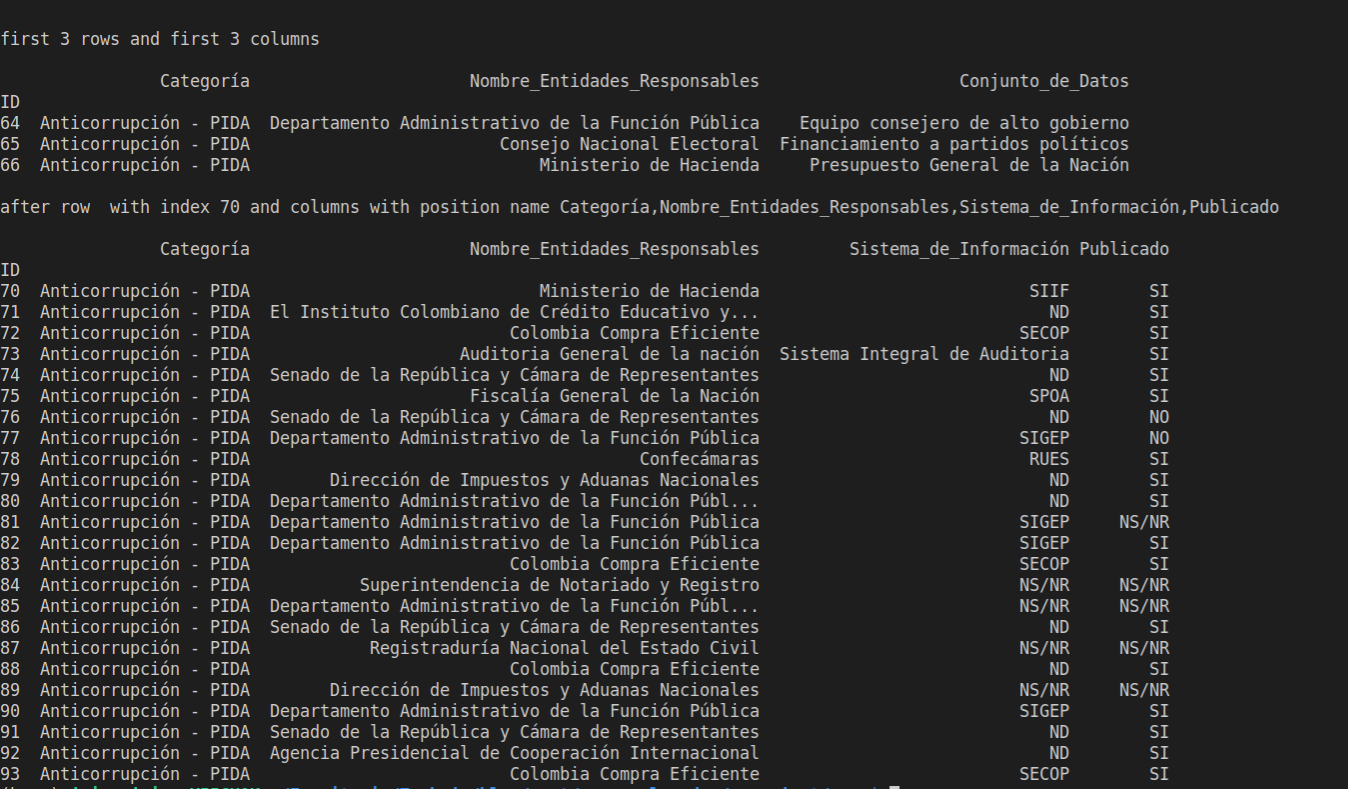
como se puede apreciar el atributo .loc es implícito, ya que el primer parámetro hace referencia al ID directamente por eso se puede traer rangos de index, y el segundo parámetro hace referencia a las columnas pero con nombres, igualmente se pueden traer columnas a partir de la ubicación de una columna, en el ejemplo ocurre con Conjunto_de_Datos, estos atributos tienen un gran potencial ya que se puede complementar además con validaciones
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def filter_data_iloc_validation():
print()
data = read_csv()
print(data.iloc[:,[0,1,2,4,5]][data.Dato_abierto=="SI"])
filter_data_iloc_validation()ejecuto y veo el resultado

Borrado
Al ser un concepto matricial cuando se requiere borrar debo preguntarme que quiero borrar filas o columnas? con esta pregunta y su respuestas clara debemos saber que borrar un dato es bastante sencillo como se aprecia en el siguiente dato
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def delete_data():
data = read_csv()
print(data.loc[64])
data = data.drop(64, axis=0)
print(data)
delete_data()
ejecuto y veo el resultado aquí
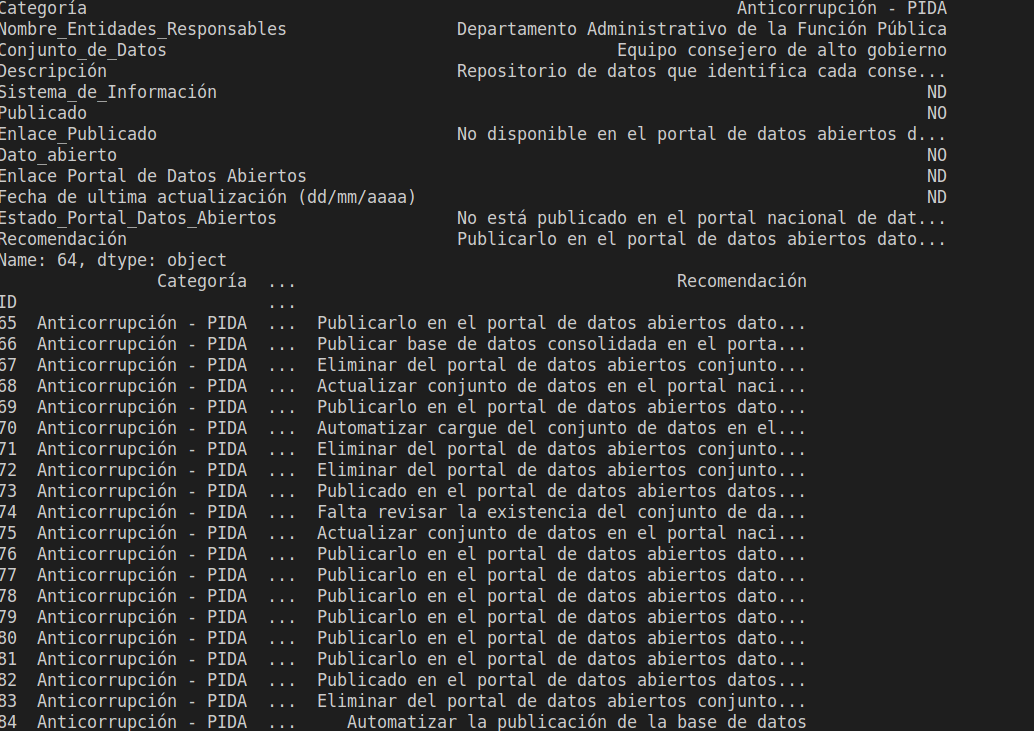
como se ve en la imagen borro el registro # 64, en el codigo tambien se aprecia que cuando cargo el csv le paso la columna que se encargara de indexar las filas esto por que pandas por defecto asigna una numeración secuencial, pero al ya tener un ID, utilizó esta columna luego llamó al método .drop que recibe como parámetro el ID, en axis paso el valor 0 debido a que 0 hace referencia a las filas (y 1 a columnas), ya que también se pueden borrar columnas, ahora lo interesante con pandas es que podemos borrar con condiciones siguiendo el concepto vectorial, es decir sin hacer foo-loops este concepto se aprecia en la explicación de la Figura para ver cómo sería el ejemplo veámoslo a continuación
para el ejemplo en las columnas borrare de la columna los datos que no son abiertos, ya que me interesan solo los abiertos para ello tengo una columna llamada Dato_abierto que tiene unos valores, necesito borrar los que tengan el valor "NO" que me indica que no es abierto, pero también podría decir "NOT", o "NEGATIVE" por ende para ello primero debo verificar que opciones hay en esa columna y para ello me valdré de la función loc
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def delete_data_filter():
data = read_csv()
print(data.loc[:, "Dato_abierto"].unique())
delete_data_filter()
ejecutó y puedo ver el siguiente resultado
['NO' 'SI' 'PARCIAL']la función .unique() se aplica agrupando las opciones posibles disponibles tomando en cuenta cada celda, con esta opción disponible ya puedo aplicar el filtro para que me borre todas las filas donde Dato_abierto tenga el valor de "NO"
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def delete_data():
data = read_csv()
print(data.loc[64])
data = data.drop(64, axis=0)
print(data)
def delete_data_filter():
data = read_csv()
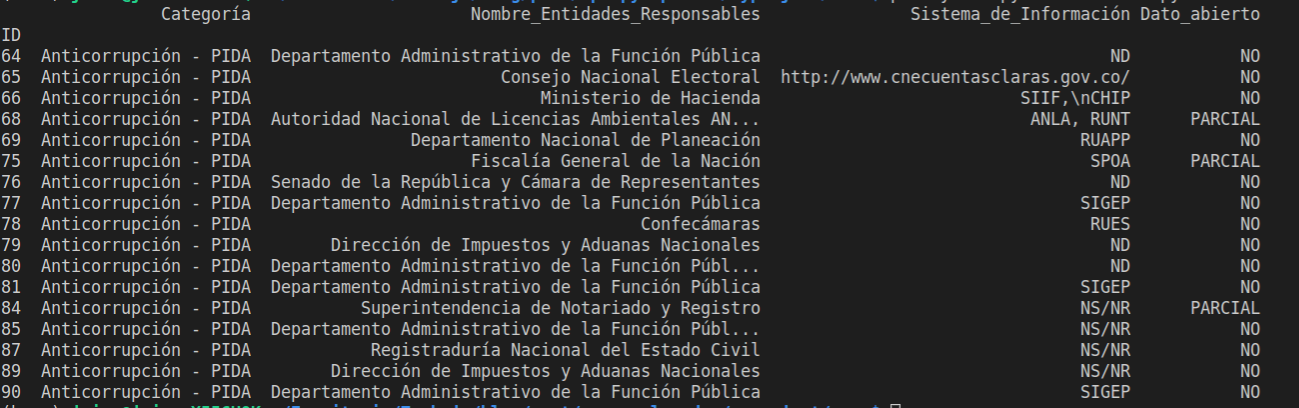
data = data.drop(data[data['Dato_abierto']=="NO"].index)
print(data.loc[:,"Dato_abierto"].unique())
delete_data_filter()
ejecuto y obtengo el siguiente resultado
['SI' 'PARCIAL']y también puedo contar los datos que hay disponible utilizando el atributo shape que devuelve una tupla con las fila y columnas

se ve que al cargar la información se tienen 30 datos y después de aplicar el borrado quedan 16 filas
Query
Este atributo es realizado para hacer consultas más eficientes que con los filtros vistos anteriormente, además de permitir construir "mask" mas complejos que este concepto en pandas permite pasar como parámetro estructuras de booleanos (muy similar a lo que hice con el borrado arriba) sin embargo a veces loc y iloc pueden quedar cortos para construir mask mas elaborados, en ese sentido entra a jugar el query atributo el cual permite construir consultas como se aprecia a continuación
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def query():
data = read_csv()
result = data.query(" Dato_abierto=='NO' or Dato_abierto=='PARCIAL'")
print(
result.loc[
:,
[
"Categoría",
"Nombre_Entidades_Responsables",
"Sistema_de_Información",
"Dato_abierto",
],
]
)
query()
ejecuto y el resultado seria
fans de sql? bueno pues el query funciona muy similar se utilizan los nombres de columnas para hacer operaciones vectorizadas en este caso trae los valores dónde Dato_abierto sea NO o PARCIAL, pero no solo es eso podemos agregar variables declaradas en el código al query que esto es una de las cosas más geniales a mi parecer, utilizando una bandera @ veamos el siguiente ejemplo
import pandas as pd
def read_csv(location: str = "conjunto_datos_abiertos.csv"):
result = pd.read_csv(location, index_col="ID")
return result
def query():
data = read_csv()
minimum_id = 80
result = data.query(" ID>@minimum_id")
print(
result.loc[
:,
[
"Categoría",
"Nombre_Entidades_Responsables",
"Sistema_de_Información",
"Dato_abierto",
],
]
)
query()
ejecuto y el resultado seria el siguiente
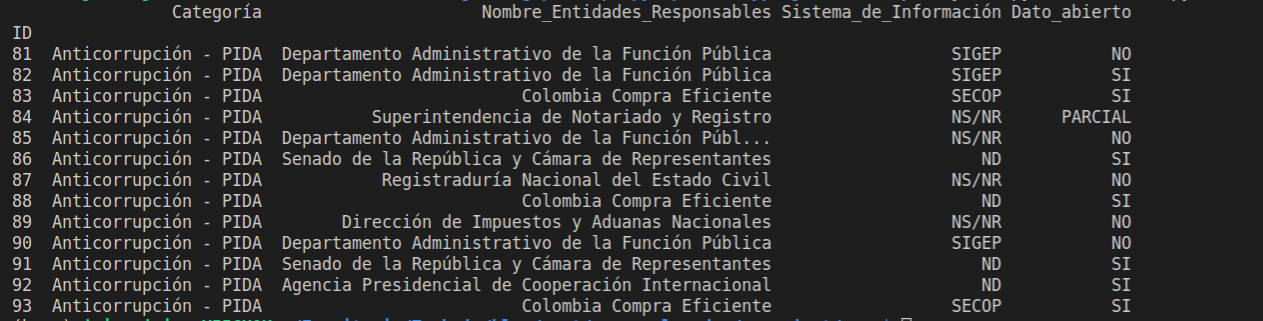
utilizando el flag @ se agrega la variable minimum_id dentro del query
Conclusiones
Pandas es una herramienta increíble que tiene una gran cantidad de funciones esto también debido a su gran tiempo que lleva en el mercado a podido recolectar un stack de atributos y funciones que facilitan el trabajo con datos tabulados, sin duda queda mucho por hablar todavía espero escribir más sobre esta gran herramienta y complementar con su gran compañero de batallas numpy