

Hace un tiempo venía utilizando para todos los trabajos relacionados a archivos de excel sobre todo para informes la librería openpyxl es una librería muy completa y que permite leer, modificar guardar y generar archivos en este formato, sin embargo me dio curiosidad si había alguna mejor manera de hacer este trabajo ya que aveces sentia que debia darle muchas vueltas para lograr algo simple y dentro de ese camino me encontré con la librería pandas una librería super genial que además de ser muy usada en el área de procesamiento de datos sigue un concepto en donde permite hacer operaciones vectorizadas, esto básicamente logrando hacer operaciones entre filas más rápido evitando también hacer tantos "loops", este concepto no solo implica mejora de rendimiento si no que sin duda logra hacer código más legible y para ser sinceros utilizando pandas he sentido que aplica el "import magic" tan nombrado python Ver Figura 1
Para entrar en materia empezaré haciendo algunos ejemplos que se pueden hacer con cada librería, la idea de este post no es hacer una comparación de rigor, sino más bien podría verse como una implementación de diferentes soluciones a un mismo problema, soy consciente que pandas es una librería más amplia y puede no ser justa la comparación, sin embargo lo hago por que puede ser tu caso en donde estes usando la librería incorrecta y escribiendo mas codigo del necesario, antes de empezar creare un entorno con poetry e instalare la librería openpyxl y pandas con los siguientes comandos
poetry add pandaspoetry add openpyxlCargar/leer
El primer método que es más usado cuando trabajamos con estos archivos es el de cargar información, iniciare cargando la data de un archivo que contiene información de cultivos de desde los años 90 el codigo seria el siguiente
Pandas
import pandas as pd
from pprint import pprint
def read_data_pandas():
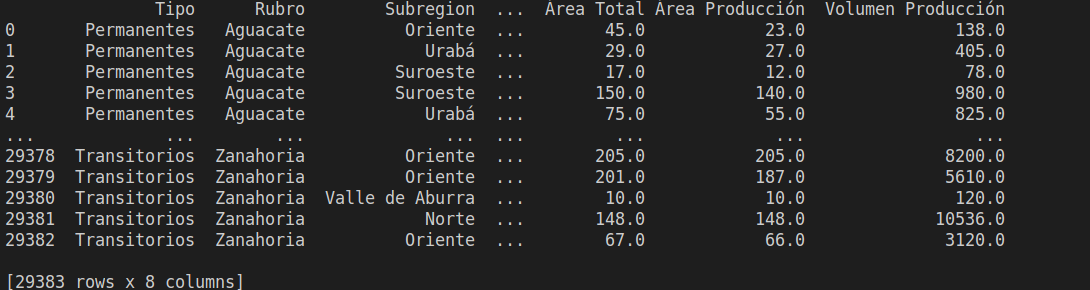
data = pd.read_excel("cultivos.xlsx")
pprint(data)
read_data_pandas()
y el resultado de ejecutar el código se puede ver a continuación
ahora la misma función pero utilizando openpyxl, aquí hay varios formas de como abrir y cargar un excel yo utilizare la más común
Openpyxl
from openpyxl import load_workbook
from pprint import pprint
def read_data_openpyxl():
file_excel = load_workbook("cultivos.xlsx")
sheet = file_excel["areas"]
for row in sheet.iter_rows(min_row=1, max_row=10):
message = ""
for cell in row:
message = message + " " + str(cell.value)
pprint("")
pprint(message)
Ejecutó y el resultado es el siguiente
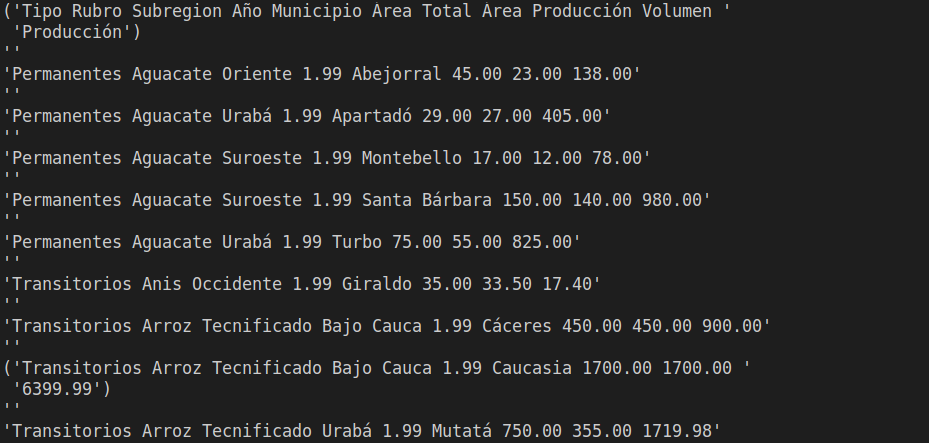
Al hacer un for-loop para recorrer los datos se le debe dar el formato uno a uno, a diferencia de pandas que el print viene dado con un formato tipo table, para no imprimir todos los datos indique un max_row de 10 para imprimir solo 10 filas
Modificar datos
Mucho de lo que se hace al tener el excel cargado es realizar modificaciones a sus datos, para ello modificare la columna Área Total y a todos sus datos le sumare el 10% de su valor actual, empezare con pandas
Pandas
import pandas as pd
from openpyxl import load_workbook
from pprint import pprint
def read_data_pandas():
data = pd.read_excel("cultivos.xlsx")
return data
def modify_data_pandas():
data_pandas = read_data_pandas()
data_pandas["Área Total Antigua"] = data_pandas["Área Total"]
data_pandas["Área Total"] = data_pandas["Área Total"] + (
data_pandas["Área Total"] * 0.1
)
pprint(data_pandas.iloc[:10,3:])
modify_data_pandas()
ejecuto el codigo y tengo como resultado lo siguiente
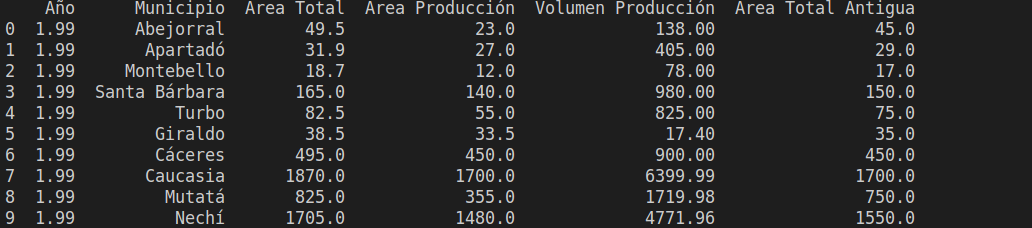
como se aprecia en el código anterior cree una columna nueva llamada Área Total Antigua que contendra la informacion de Area Total antes de sumar el 10%, esto para apreciar el cambio, adicionalmente pandas tiene una función .iloc que utilizando el slicing de python potencia el filtrado de la información, en este caso lo uso para traer las 10 primeras filas y la información después de la tercera columna ya que son muchas columnas
Openpyxl
En openpyxl se debe realizar un for-loop si bien es cierto se pueden hacer filtros solo por columna, pero cada vez que se cambie la columna el filtro también debería cambiarse por ende la opción que se podría reutilizar es recorriendo todas celdas, el código se vería de la siguiente forma
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
from pprint import pprint
def read_data_openpyxl(location: str = "cultivos.xlsx"):
file_excel = load_workbook(location)
sheet = file_excel["areas"]
for row in sheet.iter_rows(min_row=1, max_row=10):
message = ""
for cell in row:
if message == "":
message = message + str(cell.value)
else:
message = message + " " + str(cell.value)
pprint("")
pprint(message)
def modify_data_openpyxl():
file_excel = load_workbook("cultivos.xlsx")
sheet = file_excel["areas"]
sheet.insert_cols(7)
sheet["G1"] = "Area Total Modificada"
for row in sheet.iter_rows(min_row=2):
old_Value_area = 0
for cell in row:
column_letter = get_column_letter(cell.column)
if column_letter == "F":
old_Value_area = cell.value
cell.value = float(cell.value) + float(cell.value) * 0.1
if column_letter == "G":
cell.value = old_Value_area
file_excel.save("cultivos_modify.xlsx")
read_data_openpyxl("cultivos_modify.xlsx")
modify_data_openpyxl()
ejecuto el codigo y se puede ver el siguiente resultado
el código es mucho mayor que el de pandas y claramente más lento debido a que en este caso se recorren todas las celdas, además se debe conocer la estructura no pensando solamente en objetos python si no también pensando en la estructura de excel es decir en posiciones y nombres de columnas
Eliminar datos
Borrar datos es un proceso necesario cuando se cargar un archivo, se pueden dar algunas condiciones que se usen como filtro para borrar cierta información, para ello mostrare el ejemplo primero en pandas
Pandas
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
from pprint import pprint
def read_data_pandas():
data = pd.read_excel("cultivos.xlsx")
return data
def delete_data_pandas():
data_pandas = read_data_pandas()
data_pandas.drop(data_pandas[data_pandas.index<10].index, inplace=True)
pprint(data_pandas.head(10))
delete_data_pandas()
ejecuto el codigo y obtengo el siguiente resultado
como se puede apreciar utilizando operaciones vectoriales se logra borrar los primeros 10 elementos ya que por defecto cuando se carga una data pandas este se le genera un index que básicamente pertenece a su posición y se filtra utilizando la función .drop se dice que borren los elementos donde el index sea menor a 10
openpyxl
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
from pprint import pprint
def read_data_openpyxl(location: str = "cultivos.xlsx"):
file_excel = load_workbook(location)
sheet = file_excel["areas"]
for row in sheet.iter_rows(min_row=1, max_row=10):
message = ""
for cell in row:
if message == "":
message = message + str(cell.value)
else:
message = message + " " + str(cell.value)
print()
pprint(message)
def delete_data_openpyxl(amount_data=10):
file_excel = load_workbook("cultivos.xlsx")
sheet = file_excel["areas"]
sheet.delete_rows(idx=0, amount=amount_data)
file_excel.save("cultivos_modify.xlsx")
read_data_openpyxl("cultivos_modify.xlsx")
delete_data_openpyxl()
ejecuto el codigo y obtengo el siguiente resultado
con esta función se borran los primeros 10 elementos siguiendo el mismo ejemplo de pandas, pero... si se requiere hacer un filtro más complejo por ejemplo borrar los datos donde la Área Total sea par se requirira hacer un for, por el contrario pandas utiliza el concepto de filtros por vectorización sin utilizar for-loop lo cual lo hace mas eficiente
Exportar/guardar
Para finalizar veremos después de que se haga la modificación de los datos como guardar la información en un archivo excel, para ello iniciaré con pandas
Pandas
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
from pprint import pprint
def read_data_pandas(location="cultivos.xlsx"):
data = pd.read_excel(location)
return data
def save_data_pandas():
data_pandas = read_data_pandas()
data_pandas["Revisado"] = "SI"
data_pandas.to_excel("cultivos_modify_pandas.xlsx")
pprint(data_pandas)
save_data_pandas()con la función .to_excel se guarda el resultado final en el archivo de excel, ejecutando el código devuelve el siguiente resultado
lo interesante de pandas es que no solo tiene to_excel si no que tiene diferentes funciones para guardar en diferentes formatos como se aprecia en la Figura y esto es un valor agregado
openpyxl
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
from pprint import pprint
def read_data_openpyxl(location: str = "cultivos.xlsx"):
file_excel = load_workbook(location)
sheet = file_excel["areas"]
for row in sheet.iter_rows(min_row=1, max_row=10):
message = ""
for cell in row:
if message == "":
message = message + str(cell.value)
else:
message = message + " " + str(cell.value)
print()
pprint(message)
def save_data_openpyxl():
file_excel = load_workbook("cultivos.xlsx")
sheet = file_excel["areas"]
sheet["I1"] = "Revisado"
cells = sheet["I2" : "I" + str(sheet.max_row)]
for cell in cells:
cell[0].value = "SI"
file_excel.save("cultivos_modify_openpyxl.xlsx")
read_data_openpyxl("cultivos_modify_openpyxl.xlsx")ejecuto el codigo y puedo ver el resultado a continuación
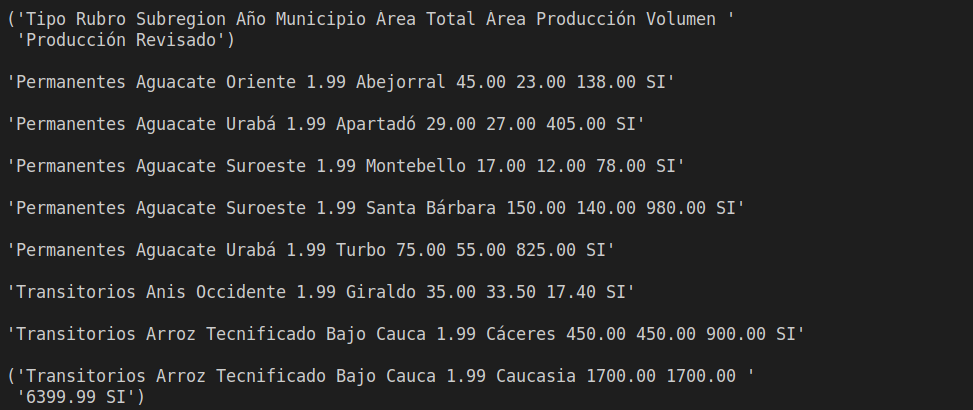
como se puede apreciar sigue existiendo la necesidad de recorrer con for cada vez que se requiere hacer un cambio masivo, por otro lado el guardar es bastante sencillo pero estos ciclos provocan que exista un tipo de código algo "mágico" con valores fijos que están ligados a la estructura del excel y hace que el código no sea tan legible como lo es en pandas
Conclusión
Las dos librerías cumplen su función como dije al principio no es una comparación de rigor y son dos librerías con funcionalidades diferentes mi propósito era mostrar que probablemente a veces usamos la librería incorrecta y forzamos trabajos que con la librería adecuada es más fácil lograr, entonce si te enfrentas a un problema donde requieres trabajar con archivos tabulados y procesarlos, la mejor opción es pandas si solo quieres generar informes o cargar información y guardarla en una base de datos openpyxl es buena opción, de pandas todavía queda un universo inmenso por explorar y espero seguir escribiendo sobre esta estupenda librería