

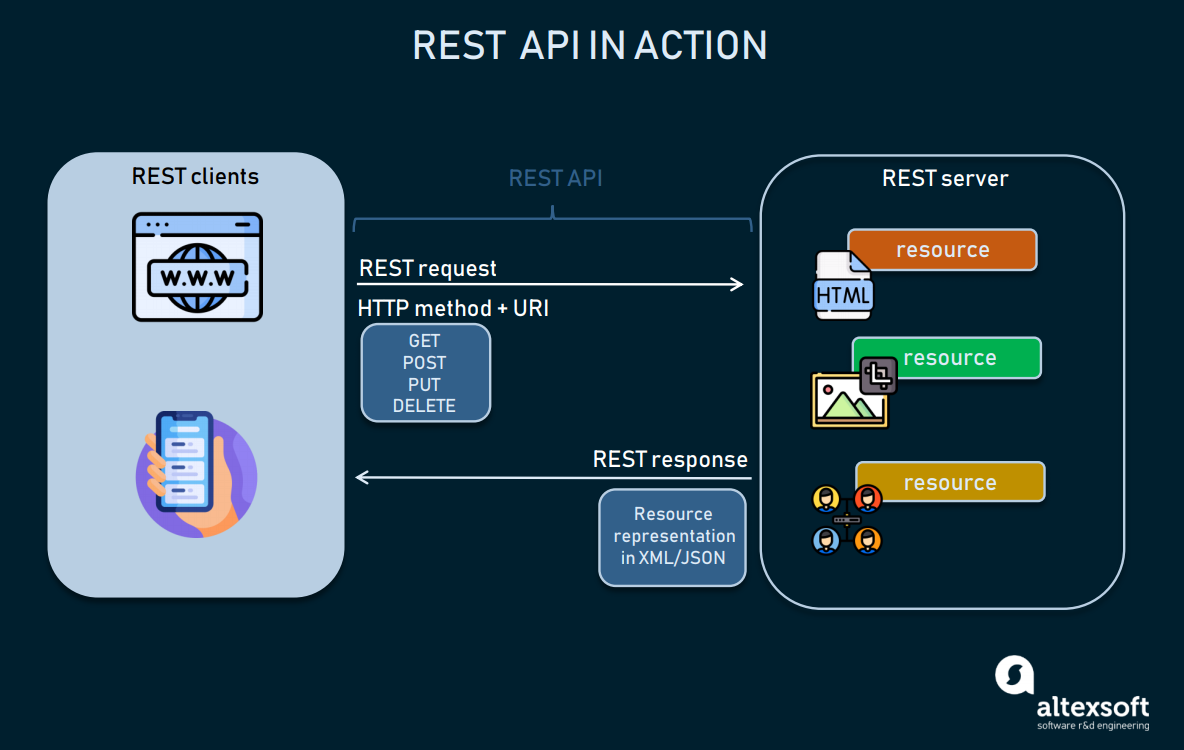
Python es un lenguaje que es multiparadigma, se puede trabajar funcional y orientado a objetos sin ningún problema, por esto mismo dentro de su librería estándar python tiene algunas herramientas que soportan estos paradigmas, podríamos pensar herramientas como los decoradores para trabajar la programación funcional, dataclasses para trabajar la programación orientada a objetos y si hablamos de asincronismo asyncio para soportar programación asíncrona, todo esto potencia los diferentes arquitecturas y formas de desarrollo, sin embargo como todo en tecnologia la mejor opción a tu problema depende de muchas variables, hoy en este artículo me tomare la tarea de analizar un enfoque pensado en la serialización de los datos, podría llamarse conversión o parseo de estructuras, este es un concepto muy utilizado en la comunicación entre APIS, ya que este proceso requiere transmitir la información entre diferentes componentes en cierto formato diferente al que se representa en memoria, el cual se puede apreciar en la siguiente Figura
Validación nativa
Generalmente los serializadores 'pythonicos' son instancias creados a partir de ciertas clases, esto se podría hacer en un proceso rudimentario de serialización y descrizalicion usando solamente clases, para ello veamos cómo sería un ejemplo
class Employer:
def __get_email(self, name:str, last_name:str):
return f"{name}.{last_name}@mycompany.com"
def __init__(self, name:str, last_name:str):
self.name = name
self.last_name = last_name
self.email = self.__get_email(self.name, self.last_name)
def serialize(self):
return self.__dict__
if __name__ == '__main__':
try:
body = {
"name":"Jairo",
"last_name":"Castañeda"
}
employer = Employer(**body)
print("Python Object")
print(employer)
print("Json object")
print(employer.serialize())
except TypeError as error:
print("The body is invalid")
Ejecutamos y obtenemos el siguiente resultado
Python object
<__main__.Employer object at 0x7f8ec8d78e50>
Json object
{'name': 'Jairo', 'last_name': 'Castañeda', 'email': 'Jairo.Castañeda@mycompany.com'}
en el código anterior ya tendríamos una base para aceptar objetos JSON, y utilizando el desempaquetamiento en python crear objetos de clase, además utilizando el atributo __dict__ convertimos el objeto de clase a un json object que sería lo que se retorna en una respuesta, podríamos ver varios problemas, a pesar de que el ejemplo anterior funciona, es bastante simple y se podría mejorar un poco de la siguiente forma
import json
class Departament:
def __init__(self, name):
self.name = name
def __repr__(self):
return f"{self.__class__.__name__}(name={self.name})"
class Employer:
def __get_email(self, name:str, last_name:str):
return f"{name}.{last_name}@mycompany.com"
def __init__(self, name:str, last_name:str, departament:Departament):
self.name = name
self.last_name = last_name
self.email = self.__get_email(self.name, self.last_name)
self.departament = departament
if isinstance(departament, dict):
self.departament = Departament(**departament)
def __repr__(self) -> str:
return f"{self.__class__.__name__}(name={self.name},last_name={self.last_name}, " \
f"email={self.email}, departament={self.departament})"
def serialize(self):
return json.loads(json.dumps(self, default=lambda value: value.__dict__))
if __name__ == '__main__':
try:
body = {
"name":"Jairo",
"last_name":"Castañeda",
"departament":{
"name":"Cloud"
}
}
employer = Employer(**body)
print("Python object")
print(employer)
print("Json object")
print(employer.serialize())
except TypeError as error:
print("The body is invalid")
Ejecutamos y obtenemos el siguiente resultado
Python object
Employer(name=Jairo,last_name=Andres, email=Jairo.Andres@mycompany.com, departament=Departament(name=Cloud))
Json object
{'name': 'Jairo', 'last_name': 'Castañeda', 'email': 'Jairo.Castañeda@mycompany.com', 'departament': {'name': 'Cloud'}}
logramos manejar objeto relacionales o anidados y modificamos como se representa el método, igualmente tenemos una gran cantidad de métodos que podemos utilizar, pero si ven la parte de serialización se vuelve muy compleja y esto realmente se vuelve insostenible, por ello debemos mirar otras opciones, entre ellas tenemos los dataclasses
Validación con dataclass
Los dataclass son un decorador en python que nos facilita trabajar con clases y nos permite de forma pythonica generar una gran cantidad de código por nosotros esto gracias a sus banderas o parámetros, los cuales logran gestionar diferentes comportamientos, veamos cómo quedaría el mismo ejemplo que teníamos anteriormente, pero ahora utilizando dataclass
from dataclasses import dataclass, asdict, field
from dacite import from_dict
@dataclass
class Departament:
name:str
@dataclass
class Employer:
name:str
last_name:str
departament:Departament
email:str = field(init=False)
def __post_init__(self):
self.email = f"{self.name}.{self.last_name}@mycompany.com"
if __name__ == '__main__':
body = {
"name": "Jairo",
"last_name": "Castañeda",
"departament": {
"name": "Cloud"
}
}
employer:Employer = from_dict(Employer, body)
print("Python Object")
print(employer)
print("Json Object")
print(asdict(employer))Ejecuto y vemos el resultado
Python Object
Employer(name='Jairo', last_name='Andres', departament=Departament(name='Cloud'), email='Jairo.Andres@mycompany.com')
Json Object
{'name': 'Jairo', 'last_name': 'Castañeda', 'departament': {'name': 'Cloud'}, 'email': 'Jairo.Castañeda@mycompany.com'}
Como se puede apreciar en el código, dataclass redujo una gran cantidad de trabajo, agregue una librería llamada dacite en poetry
poetry add daciteesta librería se encarga de la conversión de json de objeto de python, es decir recibe una clase y un objeto JSON y realiza la conversión. Los dataclass lo que hacen por debajo de todo, es sobreescribir métodos que me evitan a escribir más cantidad de código, para confirmarlo ejecutamos el siguiente linea de código sobre el objeto de python
print(dir(employer))y obtenemos el siguiente resultado
Methods
['__annotations__', '__class__', '__dataclass_fields__', '__dataclass_params__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__post_init__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'departament', 'email', 'last_name', 'name']
todos esos métodos los escribe dataclass por mi, por ello tuve que agregar un método __post_init__ que lo que hace es invocarse después de la inicialización para que se puede crear el campo email, ahora hasta aquí todo aparenta estar bien, pero qué pasa si actualizo el atributo name o last_name? el correo no se cambiara, y que pasa si necesito más validación sobre los datos, que el name tenga solo 10 caracteres o que el departamento de trabajo reciba solo unos valores predefinidos? pues existe algo llamado los property pero no se llevan muy bien con los dataclass podríamos tratar de implementar la validación de esta forma
from dataclasses import dataclass, asdict, field, InitVar
from dacite import from_dict
@dataclass
class Departament:
name:str
@dataclass
class Employer:
last_name:str
departament:Departament
name: InitVar[str]
__name:str = None
email:str = field(init=False)
def __post_init__(self, name):
self.__name = name
self.email = f"{self.name}.{self.last_name}@mycompany.com"
@property
def name(self)->str:
return self.__name
@name.setter
def name(self, name:str):
if len(name)>11:
raise ValueError
self.__name = name
if __name__ == '__main__':
body = {
"name": "Jairo",
"last_name": "Castañeda",
"departament": {
"name": "Cloud"
}
}
employer:Employer = from_dict(Employer, body)
print("Python Object")
print(employer)
print("Json Object")
print(asdict(employer))
Ejecutamos y obtenemos el siguiente resultado
Python Object
Employer(last_name='Andres', departament=Departament(name='Cloud'), _Employer__name='Jairo', email='Jairo.Andres@mycompany.com')
Json Object
{'last_name': 'Castañeda', 'departament': {'name': 'Cloud'}, '_Employer__name': 'Jairo', 'email': 'Jairo.Castañeda@mycompany.com'}
debido a los métodos que se sobreescriben, el truco de la variable privada para utilizar el property nos genera un error en la serialización, por ello debemos pensar en una librería completa cuyo trabajo es el de trabajar con objetos python, se enfoca en la serialización y validación de datos, esta librería es pydantic
Validación con pydantic
Ya en otros post he hablado de pydantic, hoy trataré de enfocarme en lo relacionado a validaciones, pydantic es básicamente una librería para gestionar todo el proceso de validación de datos forzando la validación incluso en runtime, garantizando a si que los type hints se cumplen no solo en desarrollo, veamos el código
from pydantic import BaseModel, Field, validator
from typing_extensions import Annotated
class Departament(BaseModel):
name: str
class Employer(BaseModel):
last_name: str
departament: Departament
name: str
email: Annotated[str, Field(default_factory=lambda: "")]
def __init__(self, **data):
super().__init__(**data)
self.email = f"{self.name}.{self.last_name}@mycompany.com"
if __name__ == '__main__':
body = {
"name": "Jairo",
"last_name": "Castañeda",
"departament": {
"name": "Cloud"
}
}
employer = Employer(**body)
print("Python Object")
print(employer)
print("Json Object")
print(employer.dict())
Ejecutamos y obtenemos el siguiente código
Python Object
last_name='Castañeda' departament=Departament(name='Cloud') name='Jairo' email='Jairo.Castañeda@mycompany.com'
Json Object
{'last_name': 'Castañeda', 'departament': {'name': 'Cloud'}, 'name': 'Jairo', 'email': 'Jairo.Castañeda@mycompany.com'}
como se puede apreciar la serialización y deserialización viene incluida en toda la herramienta y funciona bastante sencilla, ahora para agregar los validadores usamos el siguiente código
from pydantic import BaseModel, Field, validator
from typing_extensions import Annotated
class Departament(BaseModel):
name: str
class Employer(BaseModel):
last_name: str
departament: Departament
name: str
email: Annotated[str, Field(default_factory=lambda: "")]
def __init__(self, **data):
super().__init__(**data)
self.email = f"{self.name}.{self.last_name}@mycompany.com"
@validator('name')
def name_must_contain_space(cls, v):
if ' ' not in v:
raise ValueError('must contain a space')
return v.title()
if __name__ == '__main__':
body = {
"name": "Jairo Andres",
"last_name": "Castañeda",
"departament": {
"name": "Cloud"
}
}
employer = Employer(**body)
print("Python Object")
print(employer)
print("Json Object")
print(employer.dict())
los validadores en pydantic se ponen a nombre de los atributos, puedo recibir solo el atributo a modificar o todos los atributos si lo que deseo es modificar el atributo en función de los demás, con esta sencilla linea de codigo ya tengo la validación si ejecuto el código incumpliendo la regla obtengo este error
Traceback (most recent call last):
File "main_pydantic.py", line 34, in <module>
employer = Employer(**body)
File "main_pydantic.py", line 16, in __init__
super().__init__(**data)
File "pydantic/main.py", line 331, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for Employer
name
must contain a space (type=value_error)
Conclusiones
Las librerías que nos permiten serialización sin contar las que son propias de los frameworks (como django rest framework) son librerías livianas e independientes del framework, incluso podría modelar el dominio usandolas por que son librerías realizadas para eso, construccion de modelo de datos, cual es la mejor? esa respuesta no la puedo dar, pero el proceso comparativo tiene que tener en cuenta por lo menos variables como rendimiento, peso de la librería y arquitectura sobre la cual se esta desarrollando el proyecto, con estas variables y una calificación basada en la teoría y la prueba podríamos obtener la que mejor se adapta a nuestro contexto
Te gusto el post y quisieras poder aplicar lo aprendido?
