

AWS S3 es un servicio para alojamiento de objetos, tiene varias características que nos permiten tener varias opciones de tipos de almacenamiento, es un servicio que he utilizado en los proyectos que estoy involucrado, recientemente he podido implementar y documentar algunas funciones que me parecen interesante las cuales mostraré a continuación
Antes de ir a los ejemplos necesitamos instalar Boto3 que es una librería encargada de permitirnos comunicarnos con la suite de servicios de AWS en python, entonces ejecutamos el siguiente comando en mi caso usare python 3.7
pip install boto3adicionalmente Boto3 lee la información de acceso desde un archivo ubicado en ~/.aws/config si ya tienes instalado el aws cli este archivo ya debería existir si no debes crearlo y agregar los siguientes datos de acceso
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEYestos datos los obtienes desde el servicio IAM de AWS, también agregaremos una última librería llamada python-magic que explicaremos su uso en el código
pip install python-magic1. Guardar un archivo con su content type
Guardar un archivo en un folder dentro de un bucket es la función más básica que se podría hacer, sin embargo veremos que con algunos parámetros obtenemos una mejora tanto en código como en funciones, un contexto ideal para asignarle un content type a un archivo es cuando queremos guardar por ejemplo un pdf y que se cargue en el navegador, pero también puede ocurrir con otros tipos de archivos, además esto le agrega información adicional a la hora de descargarse para que se interprete mejor, la implementación se visualiza en el siguiente código
import boto3
import magic
class AWSS3:
def __init__(self) -> None:
self.s3_resource = boto3.resource("s3")
self.bucket = self.s3_resource.Bucket("my-bucketpublic")
def upload_file(self, file_upload):
self.bucket.put_object(
Key="mydocument.pdf",
Body=file_upload,
ACL="public-read",
StorageClass="STANDARD",
ContentType=magic.from_buffer(file_upload[0:2048], mime=True),
)
my_image = None
with open("technology-radar-vol-23-es.pdf", mode="rb") as file_image:
my_image = file_image.read()
my_s3 = AWSS3()
my_s3.upload_file(file_upload=my_image)
Y ejecutamos el código
python main.py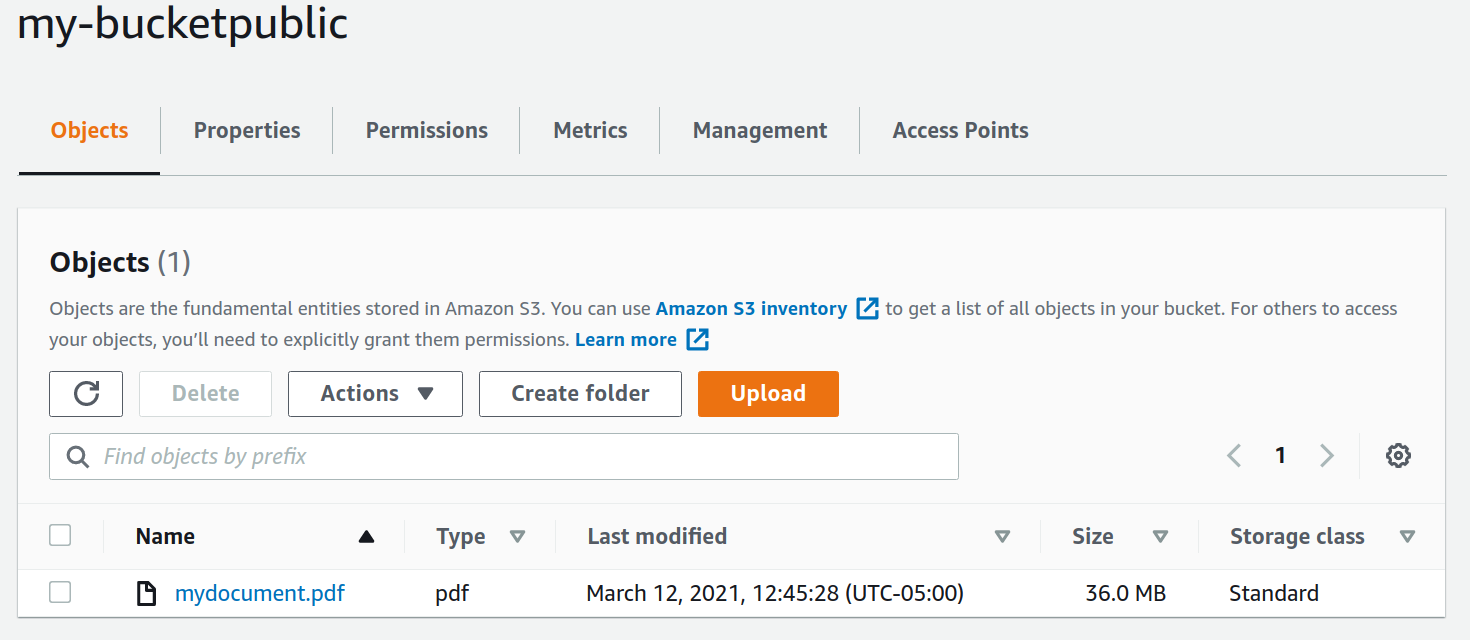

Explicare un poco el código
class AWSS3:
def __init__(self) -> None:
self.s3_resource = boto3.resource("s3")
self.bucket = self.s3_resource.Bucket("my-bucketpublic")
def upload_file(self, file_upload):
self.bucket.put_object(
Key="mydocument.pdf",
Body=file_upload,
ACL="public-read",
StorageClass="STANDARD",
ContentType=magic.from_buffer(file_upload[0:2048], mime=True),
)creamos una clase con un constructor en donde se inicializa el recurso S3 y el bucket al cual se va a acceder, después de ello vemos un método llamado upload_file este recibe el archivo en bytes como parámetro, aquí se llama al método put_object de la instancia del bucket inicializada en el constructor donde se pasan los siguientes parámetros
- Key este es el nombre del archivo que lo hace único (si se encuentra dentro de un folder debe llevar el nombre de ese folder)
- Body el archivo a guardar en bytes
- ACL son los permisos que tendrá el archivo en este caso es público y de lectura
- StorageClass el tipo de almacenamiento en el cual se guardará AWS tiene varias opciones y a partir de este depende el costo de almacenamiento
- ContentType este es el media type del archivo y permite leer algunos de tipos de archivos usando el navegador, es muy útil por ejemplo para guardar archivos pdf
En este parámetro se usa una librería llamada magic la cual retorna el media type de un archivo, para hacerlo más eficiente lo mejor es pasar solamente los primeros 2048 bytes del archivo, este al ser pdf retorna algo como esto 'application/pdf' para imágenes cambiaria lo mismo para archivos excel, el código final ya es abrir el archivo en memoria y llamar al método de upload_file.
Utilizar este content type es bastante útil junto con la librería magic sobre todo cuando se están recibiendo archivos de diferentes tipos en una API que expone algún servicio de carga de archivos
2. Generar una url temporal para consultar un archivo
Como vimos anteriormente se puede guardar un archivo público pero también se puede guardar como privado, cuando esto sucede no es accesible solamente con la url si no que debe tener o existir algún tipo de autentificación, en este caso para consultar un archivo utilizaremos algo llamado signed url o url temporal la cual podemos generar por tiempo limitado, aquí para el ejemplo he cambiado los permisos del archivo anterior y lo he dejado solo privado
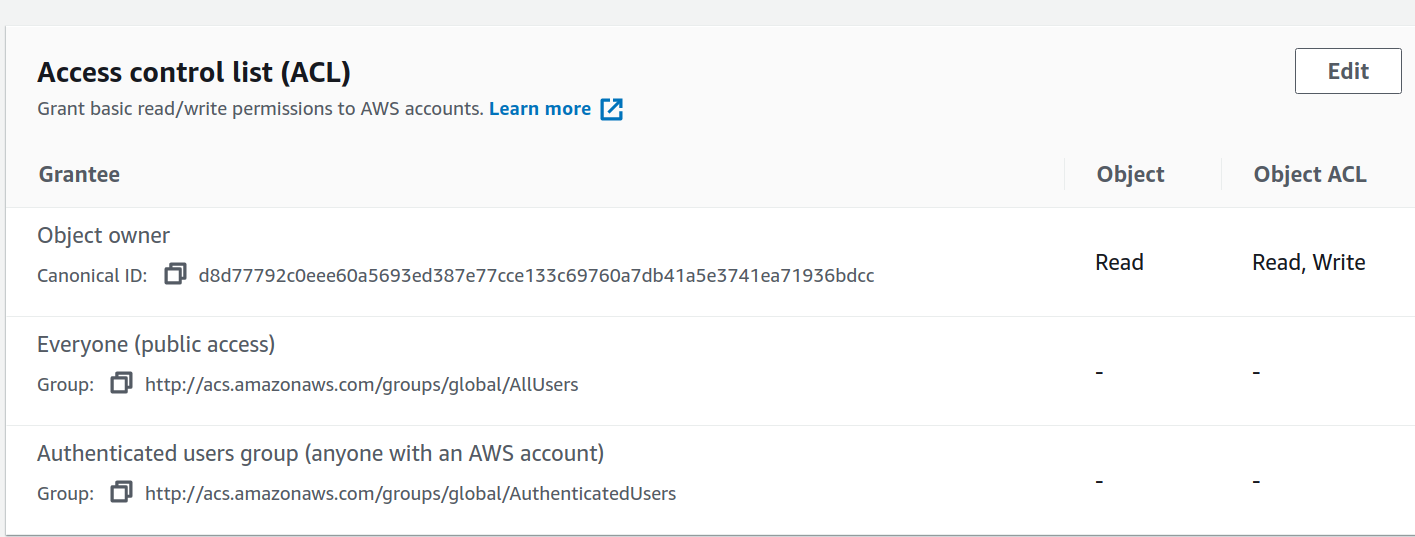
para poder generar el url temporal debemos implementar el siguiente código
import boto3
import magic
class AWSS3:
def __init__(self) -> None:
self.s3_resource = boto3.resource("s3")
self.bucket = self.s3_resource.Bucket("my-bucketprivate")
self.s3_client = boto3.client("s3")
def get_url_location_file(self, key_name: str) -> str:
response = self.s3_client.generate_presigned_url(
"get_object",
Params={
"Bucket": "my-bucketprivate",
"Key": key_name,
},
ExpiresIn=60,
)
return str(response)
my_s3 = AWSS3()
print(my_s3.get_url_location_file("mydocument.pdf"))Ejecutamos el código
python main.pyhttps://my-bucketprivate.s3.amazonaws.com/mydocument.pdf?AWSAccessKeyId=AKIAUHHFBM4CJUPVNMGO&Signature=ivr7Vg3vTLfE6HJSyrJn9lMqQbw%3D&Expires=1615574241
Vayamos un poco al código
def get_url_location_file(self, key_name: str) -> str:
response = self.s3_client.generate_presigned_url(
"get_object",
Params={
"Bucket": "my-bucketprivate",
"Key": key_name,
},
ExpiresIn=60,
)
return str(response)en el constructor definimos una variable s3_client la cual nos dará acceso al método generate_presigned_url este metodo recibe los siguientes parametros
- 'get_object' es una bandera para indicar que se quiere obtener el archivo (este parámetro para generar esta url es fijo)
- Params es un dict que contiene el nombre del bucket y el key_name de mi archivo
- ExpiresIn es el tiempo de vida de la url que se generara en este caso serán 60 segundos
Finalmente el response devuelve una url la cual queda solo ingresar, esta url después de generada tiene el limite de tiempo establecido en el ExpiresIn después de este tiempo la url generara un error, esta característica es muy útil cuando se maneja AWS S3 como servicio de almacenamiento de una app que tiene diferentes permisos y se requiere que el documento no esté publico y para consultarlo se usa intervalos de tiempo
3. Configurar ciclo de vida de un objeto en AWS S3

AWS S3 tiene diferentes tipos de almacenamiento y diferentes opciones de borrado, una de ellas es borrar un objeto o cambiarlo a otra clase de almacenamiento dependiendo de un ciclo de tiempo, esto es bastante útil por que muchas veces se crean archivos temporales que se pueden borrar al pasar un día o incluso menos, para utilizar esta interesante función veremos la siguiente porción de código
import boto3
from io import BytesIO
import magic
class AWSS3:
def __init__(self) -> None:
self.s3_resource = boto3.resource("s3")
self.bucket = self.s3_resource.Bucket("my-bucketprivate")
self.s3_client = boto3.client("s3")
def set_life_cycle_folder(self, folder:str)->None:
bucket_lifecycle_configuration = self.s3_resource.BucketLifecycleConfiguration(
"my-bucketprivate"
)
response = bucket_lifecycle_configuration.put(
LifecycleConfiguration={
"Rules": [
{
"Expiration": {"Days": 1},
"ID": "delete-temp-files",
"Filter": {"Prefix": folder},
"Status": "Enabled",
}
]
}
)
my_aws_s3 = AWSS3()
my_aws_s3.set_life_cycle_folder("files-temp/")
Ejecutamos el código y visualizamos el resultado
python main.py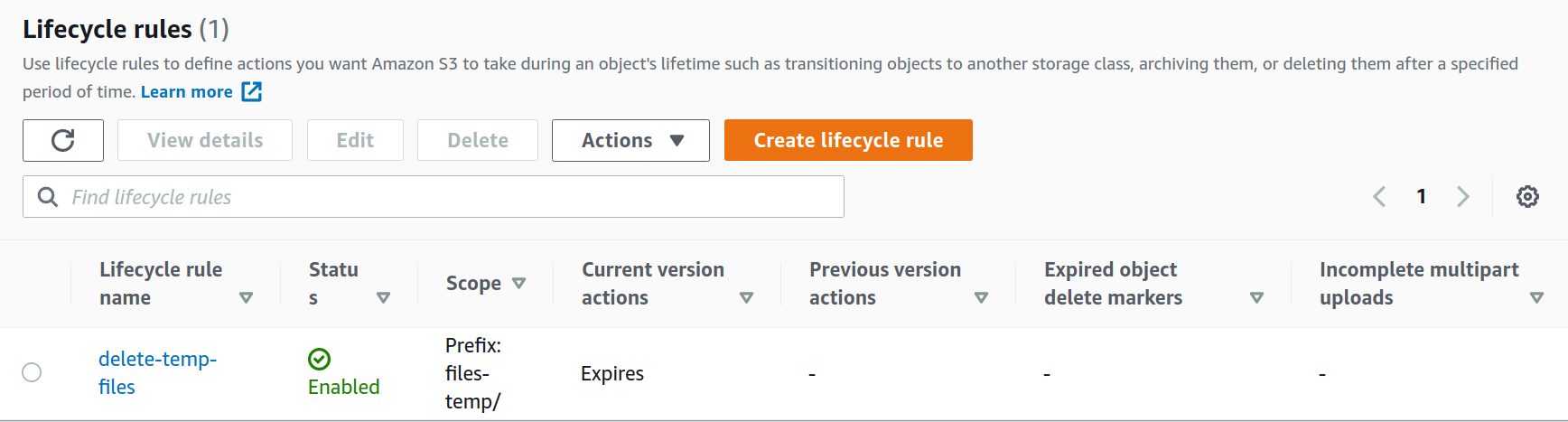
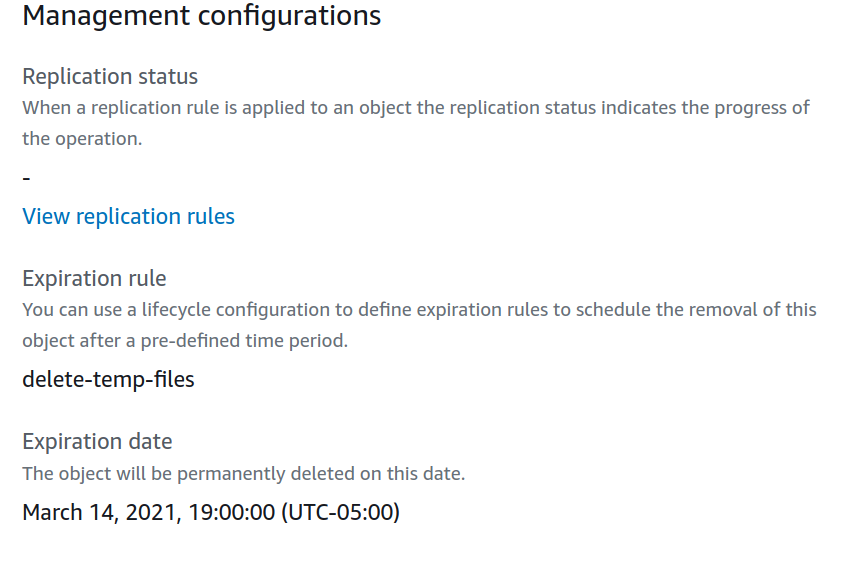
Revisemos un poco el codigo del metodo set_life_cycle_folder, este metodo nos recibe como parámetro el nombre del folder donde se pondrá la regla de ciclo de vida, seguido se obtiene una instancia de BucketLifecycleConfiguration este recibe como parámetro el nombre del bucket dentro del cual se encuentra el folder, de aquí se llama al método put el cual recibe un dict como parámetro llamado LifecycleConfiguration de esta información que recibe nos enfocaremos en rules que es la importante este recibe los siguientes parámetros:
- Expiration aquí le podemos especificar una fecha exacta en donde queremos que caduque los archivos o podemos utilizar dias , que en este caso se ha utilizado 1 dia
- ID que es un nombre cualquiera para identificar la regla dentro del sistema de AWS
- Filter que contiene le Prefix que es el folder al cual se le pondrá la regla es importante aclarar que todo lo que se guarde aqui, asi este dentro de otra carpeta estará cobijado por esta regla
- Status puede ser Enabled o Disabled es para activar o desactivar la regla, en este caso la dejamos activa
Al final llamamos el método y pasamos como folder o prefijo la carpeta files-temp/, aquí hay un sin fin de parametros para usar, se puede no solo programar eliminados si no también programar cambios de tipo de almacenamiento es muy útil para carpetas de archivos que al principio se usan mucho pero después empieza a quedar solamente como backup y se pueda ahorrar dinero haciendo buena configuración , además es importante aclarar que por estas funciones AWS no nos cobra
4. Descargar archivos livianos en memoria
Muchas veces al usar AWS S3 como "disco duro" no se tiene la capacidad para guardar archivos de manera local por ello esta función ayuda a que si se requiere descargar un archivo para realizar cualquier validación no se escriba en disco si no que quede directamente en memoria, para ello veremos el siguiente ejemplo de código
class AWSS3:
def __init__(self) -> None:
self.s3_resource = boto3.resource("s3")
self.bucket = self.s3_resource.Bucket("my-bucketprivate")
self.s3_client = boto3.client("s3")
def get_file_in_memory(self)->BytesIO:
faker_memory = BytesIO()
self.s3_client.download_fileobj('my-bucketprivate', 'mydocument.pdf', faker_memory)
faker_memory.seek(0)
return faker_memory
my_s3 = AWSS3()
file_bytes = my_s3.get_file_in_memory_s3().read()
print(magic.from_buffer(file_bytes[0:2048], mime=True))ejecutamos el código y vemos el resultado
python main.pyapplication/pdfHablemos un poco del método que hemos agregado get_file_in_memory este método empieza declarando una instancia de BytesIO que nos servirá como espacio de memoria donde guardaremos el archivo descargado, utilizamos el método download_fileobj del cliente s3 declarado en el constructor, este recibe 3 parámetros
- Nombre del bucket en donde se aloja el archivo
- El keyname del archivo que es el nombre del archivo (si se encuentra en alguna carpeta debe llevar el nombre de la carpeta (por ejemplo myfiles/myarchivo.pdf)
- Y el tercer parámetro viene siendo el faker, o el objeto de tipo BytesIO donde guardaremos el resultado de descargar este archivo
Finalmente lo retornamos, y lo leemos para poder imprimir el media type del archivo que en este caso efectivamente es un pdf
Estos son algunos "trucos" que cuando se usa AWS S3 es buena idea tenerlos presente, muchas veces de pronto la documentacion no tiene los suficientes ejemplos y se vuelve algo confuso o complicado lograr hacer alguna implementación, la finalidad de este post fue poder aterrizar esos ejemplos, adicional quiero recalcar que todas configuraciones se pueden hacer desde aws cli, desde la interfaz o desde un cliente en diferentes lenguajes.