


spaCy es una librería de código abierto para el procesamiento del lenguaje natural, es una herramienta muy potente y que nos puede ser de mucha ayuda en nuestros proyectos en donde se trabaje con clasificaciones de textos, recientemente me ha sido muy útil para un proyecto relacionado con a un analizador de tweets sobre diferentes temas y he querido hablar un poco, además recientemente se lanzó la nueva versión y trae consigo unas nuevas features muy interesantes que también quiero mostrar, este post será introductorio ya que esta librería tiene muchos temas sobre los cuales podemos hablar, sin mas podemos pasar a los ejemplos.
Antes que nada necesitamos instalar algunas librerías para mi caso utilizare python 3.8 y poetry para la gestión de paquetes, primero agregare spaCy y seguidamente necesitaremos agregar el modelo entrenado con el lenguaje de español (para realizar todo su procesamiento de lenguaje, spacy utiliza modelos pre-entrenados)
poetry add spacypoetry run python -m spacy download es_core_news_smEn este caso utilizare un modelo básico ya que es bastante liviano sin embargo del mismo lenguaje existen modelos más completos, pero la descarga puede tomar más tiempo. Ahora una de las bases mas importantes para spaCy son los token, estos podríamos definirlos de la siguiente manera
Token
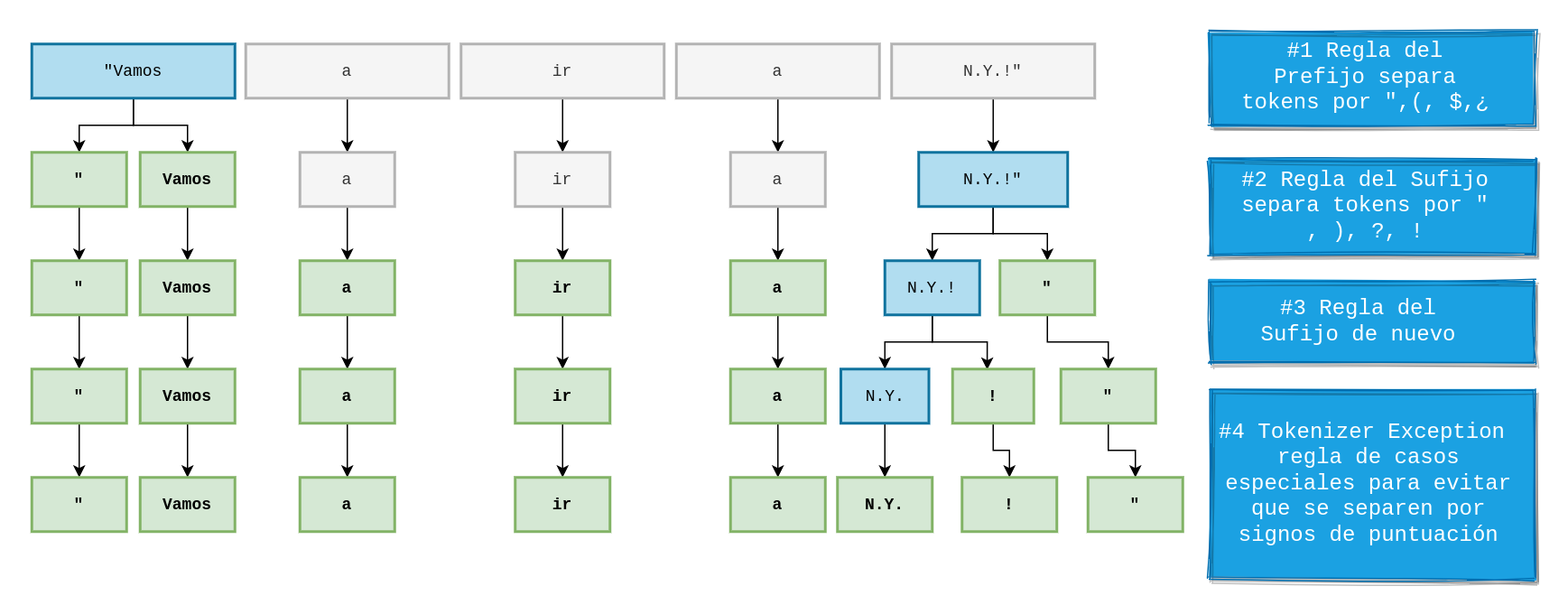
Los tokens consisten en una lista en donde cada elemento de esta lista puede ser una palabra, un signo de puntacion un nombre propio, nombre una organización una fecha, un número etc este procesamiento lo hace internamente spaCy teniendo en cuenta las reglas del propio lenguaje (ver Figura 1), siempre que le demos un texto esta librería lo "tokenizara" entregándonos una lista de tokens, donde además estos tokens contienen un conjunto de atributos con los cuales nos permitirá construir logica alrededor de ello, veamos un poco de código
import spacy
from spacy import displacy
def clear_text():
nlp = spacy.load("es_core_news_sm")
tweet = "Facebook el dia 19 de marzo del 2021 presento algunos inconvenientes"
doc = nlp(tweet)
options = {
"compact": True,
"bg": "#09a3d5",
"color": "white",
"font": "Source Sans Pro",
}
displacy.serve(doc, style="dep", options=options)
clear_text()
Ejecutamos el código y podemos ver los resultados
poetry run python main.py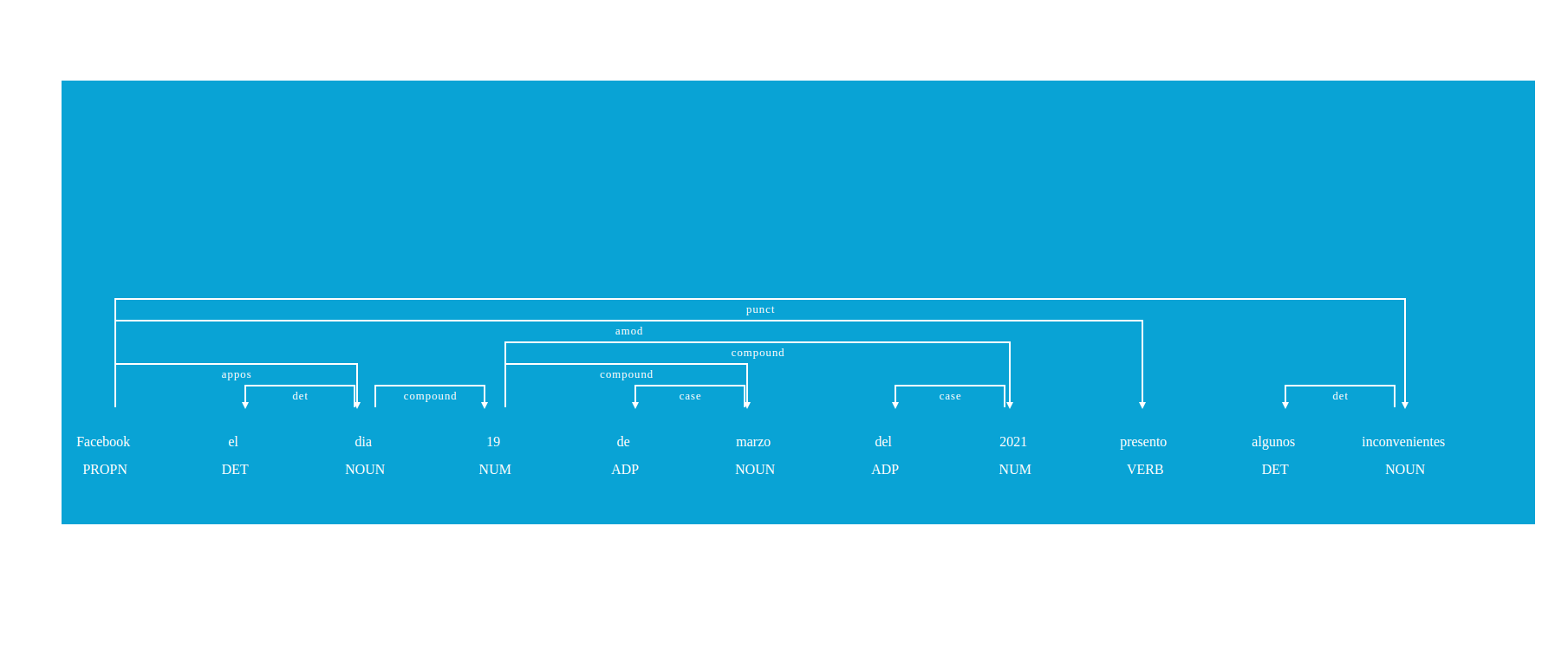
Al ejecutar main.py spaCy nos levanta un servicio en el puerto 5000 y podemos encontrar la siguiente imagen la cual nos permite ver los tokens con su tipo y su categoría/clasificación, es algo muy interesante porque podemos observar de forma gráfica nuestro texto adicionalmente podríamos pintar varios textos en varias imágenes al tiempo.
En la imagen notamos la palabra Facebook lo toma como un PROPN, es decir un nombre propio de alguna persona u organización seguidamente podemos destacar 19 y 2021 que los toma como NUM que hace referencia a que son números , seguidamente podemos ver que el token presento lo detecta como un VERB que hace referencia a un verbo, el token algunos lo clasifica como un DET que es un determinante y finalmente inconvenientes como un NOUN que es un sustantivo aquí podemos ver la referencia del significado de cada uno
Vamos a explicar un poco el código escrito anteriormente
def clear_text():
nlp = spacy.load("es_core_news_sm")
tweet = "Facebook el dia 19 de marzo del 2021 presento algunos inconvenientes"
doc = nlp(tweet)
options = {
"compact": True,
"bg": "#09a3d5",
"color": "white",
"font": "Source Sans Pro",
}
displacy.serve(doc, style="dep", options=options)
Aquí iniciamos la función utilizando el método .load() de spacy, este método nos permite cargar el modelo pre-entrado que ya habíamos instalado previamente, luego de ello declaremos una variable tweet y la pasamos como parámetro a la instancia de spacy.load() que procesa y nos devolverá los tokens son sus respectivos valores como se mostró en la Figura 1, la variable options simplemente son un conjunto de parámetros para darle estilo a la imagen que se generó, aquí se llama a la función .serve() de displacy donde nos muestra un servicio bastante amigable corriendo en el navegador.
Los tokens no solo son un "split()" la separación la hace basado en el entrenamiento que se ha realizado de este modelo, pero más importante tenemos unos atributos que utilizaremos a continuación para limpiar nuestros textos agregando una lógica basada en estos atributos para ello veamos un ejemplo un poco más realista con el contexto de limpiar tweets para luego analizarlos, simulare la carga de tweets para no agregar mas complejidad al codigo
import json
import spacy
def load_tweets():
data_json = None
with open("tweets.json", mode="r", encoding="utf-8") as file:
data_json = json.loads(file.read())
return data_json
def convert_listwords_text(list_words):
text = ""
for word in list_words:
text = text + " " + word
return text
def clear_text():
nlp = spacy.load("es_core_news_sm")
tweets = load_tweets()
for position, tweet in enumerate(tweets):
doc = nlp(tweet["text"])
list_word = []
for token in doc:
if (
not token.is_punct
and not token.is_stop
and not token.like_url
and not token.is_space
and not token.pos_ == "CONJ"
):
list_word.append(token.lemma_)
print(f"#{str(position)} {convert_listwords_text(list_words=list_word)}")
clear_text()
usaremos un archivo que nos simulará algun metodo que carga tweets hemos puesto los siguientes "tweets" en el archivo llamado tweets.json
[
{
"text":"Recuerda los contagios de #COVID19 continúan, por ello el uso de cubrebocas es obligatorio en todos los espacios."
},
{
"text":"#LPGDatos | La OMS reporta un aumento de casos de #covid19 por tercera semana consecutiva. Imagen: @LPGDatos"
},
{
"text":"A día de hoy están ingresados por #COVID19 en las UCI de la CAM 430 pacientes, 381 en ventilación mecánica. Se han dado 3141 altas a planta (no incluyen los 1152 pacientes fallecidos hasta la fecha"
},
{
"text":"La vacuna Janssen contra el #COVID19 de Johnson & Johnson es la tercera vacuna autorizada para el uso en los Estados Unidos. Esta vacuna de 1 dosis se recomienda para personas de 18 años o más. Más sobre la vacuna Janssen de J&J: https://bit.ly/2P3bvK6"
}
]ejecutamos y podemos ver el resultado
poetry run main.py#0 recordar contagio covid19 continúar cubreboca obligatorio espacio
#1 LPGDatos | OMS reportar aumento caso covid19 semana consecutivo imagen @lpgdato
#2 a ingresado covid19 UCI CAM 430 paciente 381 ventilación mecánico 3141 alta a planta incluir 1152 paciente fallecido fecha
#3 vacuna Janssen covid19 Johnson Johnson vacuna autorizado Unidos vacuna 1 dosis recomendar persona 18 año o vacuna Janssen J&JListo, vemos como los textos de tweets.json cambiaron pero revisemos un poco el código enfocándonos en la función clear_text() para entender mejor qué sucedió
def clear_text():
nlp = spacy.load("es_core_news_sm")
tweets = load_tweets()
for position, tweet in enumerate(tweets):
doc = nlp(tweet["text"])
list_word = []
for token in doc:
if (
not token.is_punct
and not token.is_stop
and not token.like_url
and not token.is_space
and not token.pos_ == "CONJ"
):
list_word.append(token.lemma_)
print(f"#{str(position)} {convert_listwords_text(list_words=list_word)}")Cargamos el modelo del idioma liviano español, adicionalmente ahora se simula una lista de tweets que se van a recorrer y se procesaran una por una, luego de esto se ingresan al modelo utilizando nlp() para que spacy haga su "magia" y tokenize cada texto, al principio mencione que los tokens tienen algunos atributos y describiremos los atributos que llamamos en el código a continuación
- is_punct retorna un booleano diciendo si el token actual es un signo de puntuación por ejemplo (. , : ;)
- is_stop devuelve un booleano si el token es un stop word , las stopword son palabras que generalmente no agregan mucha información al contexto y son poco informativas aquí entran algunas conjunciones verbos comunes y preposiciones como por ejemplo (y, ser , para, por)
- like_url retorna verdadero si el token luce como una url, generalmente los tweets pueden contener urls y en este caso las urls son irrelevantes por lo que se remueven ejemplo de las urls (https://bit.ly/2P3bvK6)
- is_space retorna verdadero si el token es un espacio, al final es buena opción eliminar estos tokens a pesar de que cuando se reconstruye el texto se incluye un espacio para separar los tokens, pero esto puede ahorrar tener tokens que no agreguen valor en el análisis
- pos_ retorna un string con la etiqueta donde se enmarca el token y lo clasifican en una categoría de las que tenemos disponible aquí en el ejemplo actual eliminamos las conjugaciones ya que son conectores que la mayoría de veces no agrega mucho contexto
- lemma_ este devuelve la forma base o la forma más sencilla de una palabra por ejemplo reporta la lematización es reportar, ingresados es ingresado un verbo en diferentes conjugaciones (bailamos , bailan, bailan) son diferentes formas de decir bailar , esto es útil ya que ayuda a reducir textos sin embargo esto es costoso y depende del lenguaje por lo tanto depende de la eficacia en la que se entrenó el modelo
Finalmente en el código llama a un método que convierte la lista de tokens a un texto formateado, es importante aclarar que los métodos que se llaman como mencione anteriormente dependen del modelo y del lenguaje por tanto su eficacia muchas veces tienen un costo pues si se requieren más características se debe utilizar el modelo más completo o en algunos casos re-entrenar estos modelos para obtener un mejor performance.
Me gustaría recalcar que esta librería es inmensa permite hacer una gran cantidad de tareas entre las cuales se puede mejorar los modelos entrenados para darle el contexto que cada problema requiere, en este artículo vimos una introducción en donde se tocaron temas algo superficiales pero que pueden presentar un buen inicio para los que empiezan a utilizarla, la idea principal es poder seguir esta serie de artículos con esta librería y complementar con artículos sobre el servicio como IBM WATSON y cargar información real de twitter
Quiero dejarles unos enlaces que seguro les pueden servir
- Conferencia de sobre análisis de tweets usando spaCy
- spaCy 101
- Proyecto en construcción (espero terminar y mejorar algun dia)