
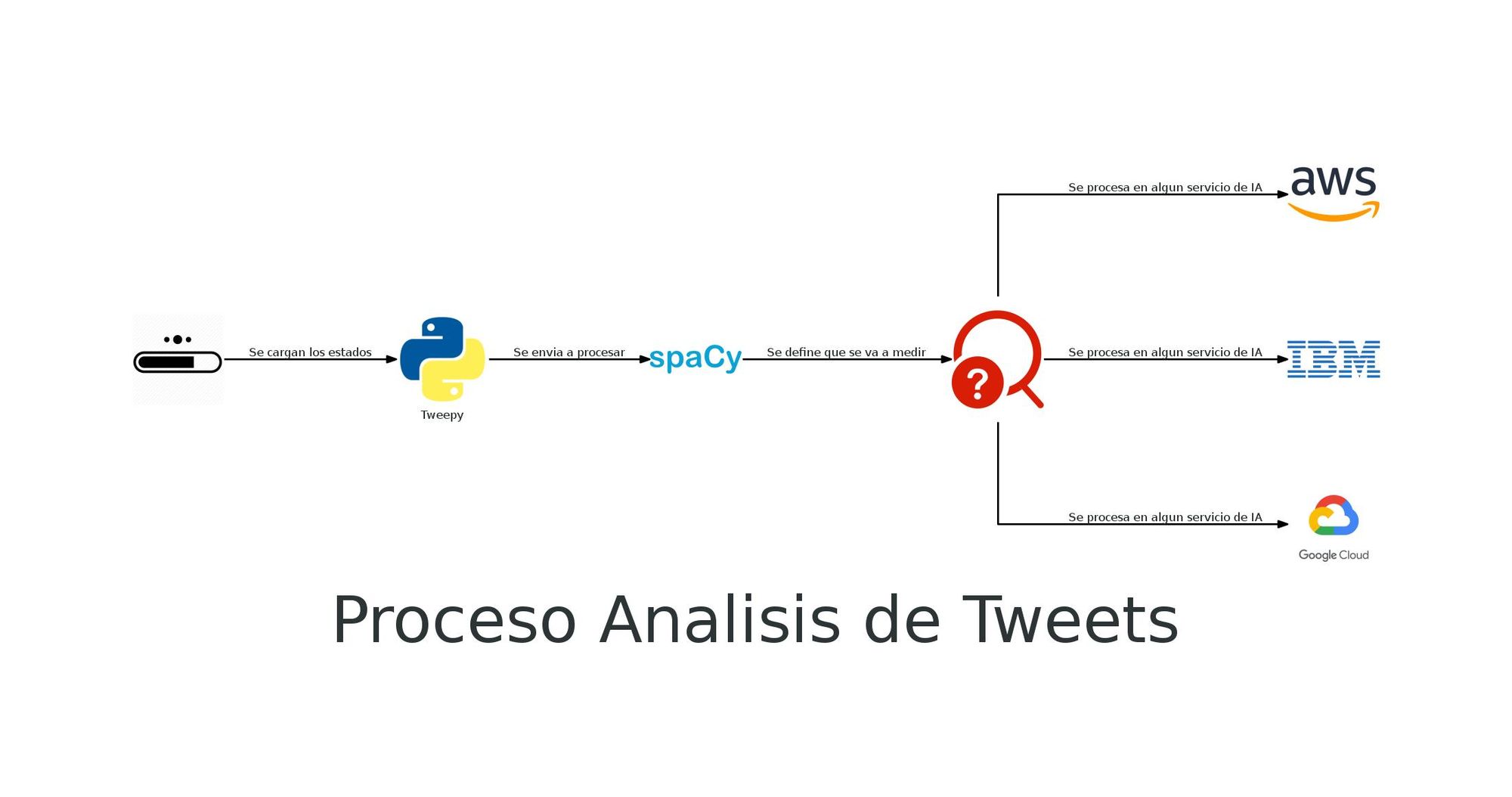
Tweepy es una librería que funciona como un "wrapper" para trabajar con la API REST de twitter, facilitando por medio de métodos y objetos en python la interacción con estos servicios, en el post anterior hablamos de cómo se podría usar spaCy para procesar y limpiar tweets, con la finalidad de seguir ese camino en este post se enfocará en cómo traer tweets con algunos filtros interesantes que podemos aplicar, y finalmente (spoiler del próximo post) seguiremos esta pequeña "metodología" descrita en la Figura 1 finalizando en un artículo que conecte con algún servicio de IA en la nube
Como siempre necesitaremos de algunas dependencias, partiremos de que usare python 3.7 y poetry como gestor de dependencias, en este caso agregaremos tweepy que es la librería principal, adicional usaremos como comodín también la librería python-dotenv para cagar variables de entorno en donde guardaremos los datos de acceso para twitter
poetry add tweepypoetry add python-dotenvAntes de seguir para poder acceder a la api de twitter deben solicitar sus credenciales en la pagina de developers twitter creando una aplicacion, con estas configuraciones ya podemos hacer el código de inicio y podemos empezar a traer información de twitter
from dotenv import load_dotenv, find_dotenv
import tweepy
import os
load_dotenv(find_dotenv())
def get_auth_tweepy():
auth_tweet = tweepy.OAuthHandler(
os.getenv("TWITTER_CONSUMERKEY"),
os.getenv("TWITTER_CONSUMER_SECRETKEY"),
)
auth_tweet.set_access_token(
os.getenv("TWITTER_ACESSTOKEN"), os.getenv("TWITTER_ACESS_TOKENSECRET")
)
return tweepy.API(auth_tweet)
def get_tweets_home():
api_auth = get_atuh_tweepy()
public_tweets = api_auth.home_timeline(count=3)
count = 0
for tweet in public_tweets:
print("")
print(f"{count}. {tweet.text}")
count+=1
get_tweets_home()
ejecutamos el codigo main.py y obsevamos el resultado
poetry run python main.py0."No trates de entender todo, a veces no se trata de entender, sino de aceptar."
1. How to Create a Reverse Shell to Remotely Execute Commands #Attacker #Java #Netcat #Payload #Perl #PHP #Python… https://t.co/OQcLTuNSBT
2. The @Suns reach 30 wins!
Chris Paul: 19 PTS, 8 AST, 2 STL
Deandre Ayton: 19 PTS, 9 REB, 2 BLK https://t.co/dqpvVRgxf0En consola ya podemos ver algunos tweets, pero expliquemos un poco el código
def get_auth_tweepy():
auth_tweet = tweepy.OAuthHandler(
os.getenv("TWITTER_CONSUMERKEY"),
os.getenv("TWITTER_CONSUMER_SECRETKEY"),
)
auth_tweet.set_access_token(
os.getenv("TWITTER_ACESSTOKEN"), os.getenv("TWITTER_ACESS_TOKENSECRET")
)
return tweepy.API(auth_tweet)La función get_auth_tweepy permiten la autenticacion en twitter, en un archivo .env he agregado las respectivas variables de entorno y utilizando python-dotenv las he cargado, de tweepy se usan dos métodos fundamentales el primero OAuthHandler el cual recibe como parámetro el consumer key y secret key este devuelve un objeto al cual se le llama al método set_access_token que recibe como parámetro el access token y el token secret (ver Figura 2) estas credenciales las obtienen desde la pagina de twitter developer como mencione anteriormente, finalmente se genera un objeto de tweepy.API con estas credenciales, al final del día este wrapper contendrá el token necesario para poder consultar la API de twitter
def get_tweets_home():
api_auth = get_atuh_tweepy()
public_tweets = api_auth.home_timeline(count=3)
count = 0
for tweet in public_tweets:
print("")
print(f"{count}. {tweet.text}")
count+=1La siguiente funcion es algo sencilla, llama al metodo de autenticacion y con este objeto llama al método home_timeline el cual recibe un parámetro count , este método cargará los tweets que deberían aparecer al entrar a twitter.com/home del usuario identificado, el filtro count funciona para cargar solamente 3 tweets, esta lista se recorre y se imprime el estado llamando al atributo text. Ahora bien, esto se puede explotar un poco mejor como veremos en el siguiente ejemplo para cagar estados, pero ahora usando el buscador con diferentes parámetros
from dotenv import load_dotenv, find_dotenv
import tweepy
import os
load_dotenv(find_dotenv())
def get_atuh_tweepy():
auth_tweet = tweepy.OAuthHandler(
os.getenv("TWITTER_CONSUMERKEY"),
os.getenv("TWITTER_CONSUMER_SECRETKEY"),
)
auth_tweet.set_access_token(
os.getenv("TWITTER_ACESSTOKEN"), os.getenv("TWITTER_ACESS_TOKENSECRET")
)
return tweepy.API(auth_tweet)
def get_tweets_home():
api_auth = get_atuh_tweepy()
public_tweets = api_auth.home_timeline(count=3)
count = 0
for tweet in public_tweets:
print("")
print(f"{count}. {tweet.text}")
count += 1
def is_retweet(tweet):
return hasattr(tweet, "retweeted_status")
def get_tweets_by_query(query_search: str):
api_auth = get_atuh_tweepy()
parameters = {
"q": query_search,
"lang": "en",
"result_type": "mixed",
"tweet_mode": "extended",
}
for status in tweepy.Cursor(api_auth.search, **parameters).items(5):
print(f"Tweet: {status.full_text}")
print(f"User: @{status.user.screen_name}")
print(f"Fecha {status.created_at}")
print(f"Es retweet? {'Si' if is_retweet(status)else 'No'}")
print("")
get_tweets_by_query("javascript")
Ejecutamos el código y vemos el resultado en consola
poetry run python main.py Tweet # 1
Tweet: Let the debate begin!
https://t.co/je1jCH8NSX
User: @ThePracticalDev
Fecha: 2021-03-26 13:39:01
Es retweet? No
Tweet # 2
Tweet: As soon as you start searching "functional programming" on the internet, you're going to hit a brick wall of academic terms that are really intimidating for someone who is learning. But don't be scared!
{ author: @crloscuesta } #DEVCommunity
https://t.co/oyZm7Ztl72
User: @ThePracticalDev
Fecha: 2021-03-26 18:31:02
Es retweet? No
Tweet # 3
Tweet: 1. Destructuring
2. Console tips
3. Dynamic key names
4. Set as a data structure
5. Callback-based APIs -> Promises
https://t.co/9XtXuwjy3Y
User: @ThePracticalDev
Fecha: 2021-03-26 13:26:01
Es retweet? No
Tweet # 4
Tweet: RT @iamBrianGraham: In future robots will cook, clean and help us around the house ! #technology #RStats #algorithms #programming #JavaScri…
User: @eljorge21
Fecha: 2021-03-27 03:37:46
Es retweet? Si
Tweet # 5
Tweet: RT @vyom_srivastava: Announcing Our New Book: Beginning iOS 8 Programming with Swift: https://t.co/dOAwZRi5UK
FEATURED #COURSES #JavaScrip…
User: @CodeAttBot
Fecha: 2021-03-27 03:37:40
Es retweet? SiAquí podemos ver cómo se están trayendo tweets no solo de home timeline si no ahora se usa el buscador, explicare un poco el codigo del metodo get_tweets_by_query
def is_retweet(tweet):
return hasattr(tweet, "retweeted_status")
def get_tweets_by_query(query_search: str):
api_auth = get_atuh_tweepy()
parameters = {
"q": query_search,
"lang": "en",
"result_type": "mixed",
"tweet_mode": "extended",
}
for status in tweepy.Cursor(api_auth.search, **parameters).items(5):
print(f"Tweet: {status.full_text}")
print(f"User: @{status.user.screen_name}")
print(f"Fecha {status.created_at}")
print(f"Es retweet? {'Si' if is_retweet(status)else 'No'}")
print("")
El método inicia autentificandose como se realizó anteriormente, después de ello se crea un diccionario con los siguientes parámetros
- q se usara este parámetro para indicar el query que se quiere buscar, puede ser un simple texto, un texto complejo utilizando utf-8 o una cuenta utilizando @nombrecuenta.
- lang indica el lenguaje en el que se quieren buscar los tweets en este caso indicamos inglés
- result_type es una bandera para traer tweets que tengan mucha interacción o simplemente traer tweets recientes, al indicar mixed se traen de los dos tipos
- tweet mode, le indica a twitter que devuelva el texto del tweet completo ya que por default lo recorta a 140 caracteres
Seguidamente para traer los tweets se utiliza la clase Cursor esta clase facilitara cargar grandes cantidades de información que muchas veces requieren ser paginadas, recibe como parámetro obligatorio la instancia de auth de tweepy y unos parámetros opcionales que son los que se han descrito anteriormente, luego se llama al método items() que recibe como parámetro la cantidad de tweets que se quieren traer, esto devuelve un iterator por ello el resultado está en un ciclo, como mencione al principio esta tool es un wrapper de la API de twitter, por lo cual para saber que devuelve se puede consultar aquí, hay atributos de geolocalización, urls, emoticones etc, para este ejemplo describiré los atributos que utilizados en el código
- full_text al especificar como parámetro que se cargue la información del tweet en formato extendido el api agrega este atributo que contiene toda la información del tweet con todos los caracteres
- screen_name es el username de la persona que realizó el tweet o el retweet
- created_at es la fecha en la que se creó el tweet formato ISO
- retweeted_status este atributo se agrega solo si el estado es un retweet, la función is_retweet lo que realiza es una inspección para verificar si efectivamente el estado contiene este atributo o no
Con esto ya podemos empezar a traer información de twitter real este articulo conecta con el artículo anterior en donde hable de spaCy y conectara con el próximo donde hablaré de trabajar con a algún servicio de IA en la nube, a continuación les dejaré el código agregando transformaciones utilizando la herramienta spaCy
import spacy
from dotenv import load_dotenv, find_dotenv
import tweepy
import os
load_dotenv(find_dotenv())
def convert_listwords_text(list_words):
text = ""
for word in list_words:
text = text + " " + word
return text
def get_atuh_tweepy():
auth_tweet = tweepy.OAuthHandler(
os.getenv("TWITTER_CONSUMERKEY"),
os.getenv("TWITTER_CONSUMER_SECRETKEY"),
)
auth_tweet.set_access_token(
os.getenv("TWITTER_ACESSTOKEN"), os.getenv("TWITTER_ACESS_TOKENSECRET")
)
return tweepy.API(auth_tweet)
def is_retweet(tweet):
return hasattr(tweet, "retweeted_status")
def get_tweets_by_query(query_search: str):
api_auth = get_atuh_tweepy()
parameters = {
"q": query_search,
"lang": "en",
"result_type": "mixed",
"tweet_mode": "extended",
}
count = 0
return tweepy.Cursor(api_auth.search, **parameters).items(5)
def clear_text():
nlp = spacy.load("es_core_news_sm")
tweets = get_tweets_by_query("javascript")
docs = []
for position, tweet in enumerate(tweets):
doc = nlp(tweet.full_text)
docs.append(doc)
list_word = []
for token in doc:
if (
not token.is_punct
and not token.is_stop
and not token.like_url
and not token.is_space
and not token.pos_ == "CONJ"
):
list_word.append(token.lemma_)
print(f"#{str(position)} {convert_listwords_text(list_words=list_word)}")
clear_text()
ejecutamos y obtenemos una salida en consola mas limpia
poetry run python main.py#0 if(code = = = clear amp;& short console.log("You're awesomar author @the_kalashinkov DEVCommunity
#1 Closure is important evir for your code author @abhishek_jain35 DEVCommunity
#2 if you're in IT security networks or SysAdmin you can give your career a lot more reach by learning a high level scripting language Python or JavaScript In this 20-min interview with @CBTNuggets trainer @cloudbart I'll give you several reasons why
#3 RT @prathkum 65 JavaScript resources that can help you Mega Thread 🧵 👇 🏻
#4 RT @jamilahmed_16 Buy 1 Get 2 offer Edureka Courses node nodejs javascript npm coding webdesign js sql
En el siguiente artículo desarrollaremos las funciones encargadas de la clasificación del texto dependiendo de unos parámetros que se definan, espero este post les haya servido y los invito a compartirlo